Learning Theory Core
PAC Learning Framework
The foundational formalization of what it means to learn from data: a concept is PAC-learnable if and only if an algorithm can, with high probability, find a hypothesis that is approximately correct, using a polynomial number of samples.
Prerequisites
Why This Matters
The PAC (Probably Approximately Correct) framework, introduced by Leslie Valiant in 1984, is the mathematical foundation for answering the most basic question in machine learning: when is it possible to learn from data?
Hide overviewShow overview
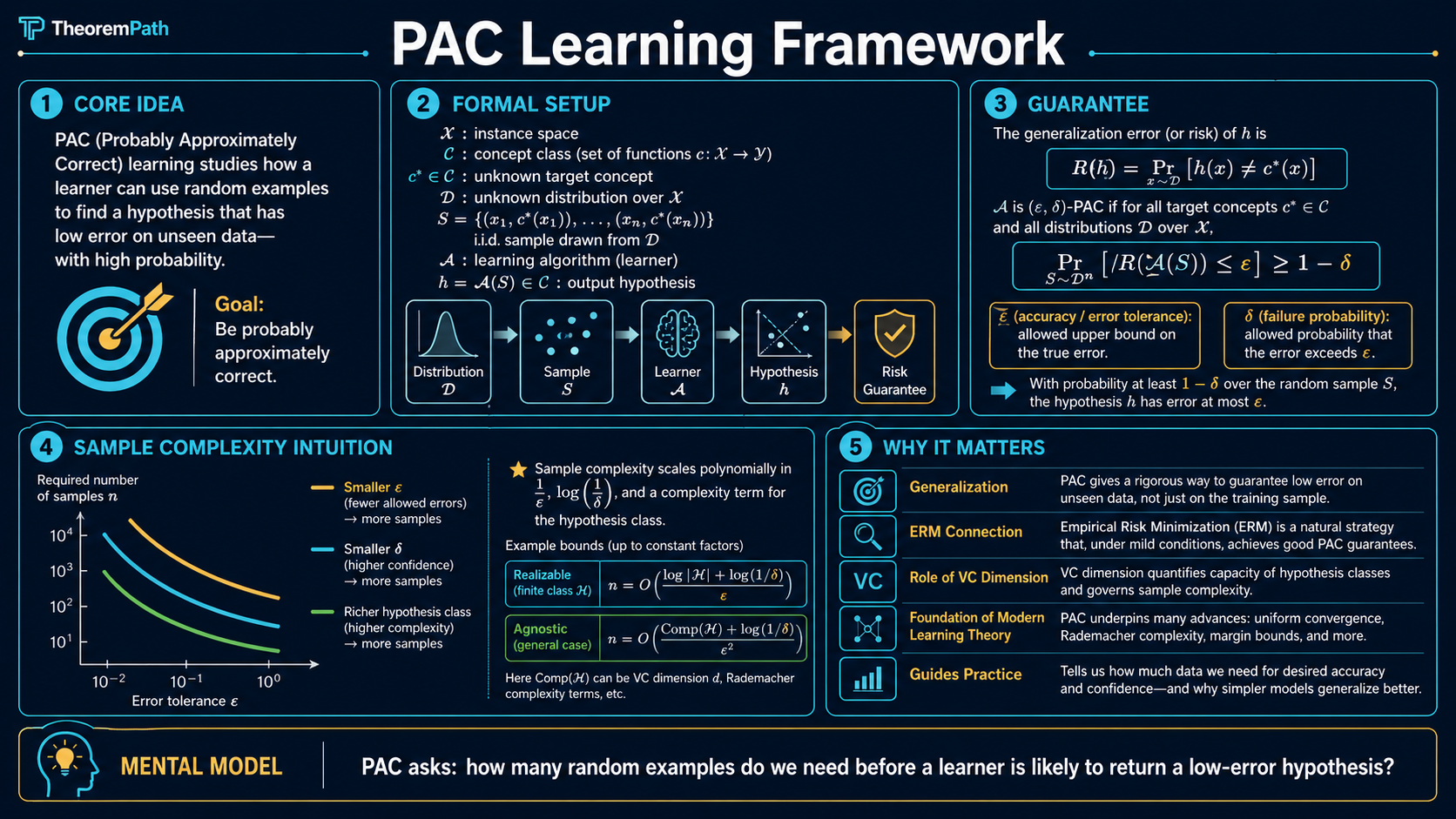
Before PAC theory, machine learning was a collection of algorithms without a unifying theory of learnability. PAC provides the definitions and theorems that tell you whether a learning problem is solvable in principle, and how many samples you need.
Every generalization bound you encounter, from ERM to VC dimension to Rademacher complexity, is ultimately answering a question that PAC theory formalized. The sample complexity bounds page covers the quantitative details.
Mental Model
Think of a learner as a detective. The detective wants to identify an unknown rule (the target concept) but can only observe examples. PAC theory asks: how many examples does the detective need to be probably () approximately () correct about the rule?
The "probably" accounts for the randomness of the training sample. you might get an unlucky draw. The "approximately" accounts for the fact that you do not need to identify the rule exactly; getting close is enough.
Formal Setup and Notation
Let be an instance space (e.g., ). A concept is a function . A concept class is a collection of concepts.
There is an unknown distribution over and an unknown target concept .
The learner receives a training sample
where each independently.
The learner outputs a hypothesis .
Generalization Error
The generalization error (or risk) of a hypothesis with respect to target and distribution is:
This is the probability that disagrees with on a random example.
Core Definitions
PAC Learnability (Realizable Case)
A concept class is PAC-learnable if and only if there exists an algorithm and a function such that for every target concept , every distribution over , every accuracy parameter , and every confidence parameter :
when is given a sample of size drawn i.i.d. from and labeled by , it outputs satisfying:
The class is polynomial-sample PAC-learnable if is polynomial in and . It is efficiently PAC-learnable (also called polynomial-time PAC-learnable) if, in addition, runs in time polynomial in , , and . This follows the standard usage in computational learning theory (Valiant 1984, Kearns and Vazirani 1994), where "efficient" always refers to time, not sample, complexity.
The key features of this definition:
- For all distributions. The learner must work regardless of
- For all target concepts. The learner must work for any
- Probably: the guarantee holds with probability
- Approximately: the error is at most , not necessarily zero
Sample Complexity
The sample complexity is the minimum number of training examples needed to achieve error with confidence . This is the fundamental quantity that PAC theory characterizes.
Realizable vs. Agnostic PAC
Realizable Setting
In the realizable setting, we assume . The target concept is in our hypothesis class. The learner can achieve zero training error. The question is whether zero training error implies low test error.
Agnostic PAC Learning
In the agnostic setting, we make no assumption about the target. Labels may be generated by any joint distribution over . The goal is to compete with the best hypothesis in :
This is harder because even the best hypothesis in may have nonzero error (the approximation error). Agnostic PAC learning requires more samples.
The agnostic setting is more realistic: in practice, you never know if the true relationship is exactly representable by your model class.
What breaks when realizability is dropped. Under realizability, the single-hypothesis tail used , which is a Bernoulli-on-clean-flips event: each independent example has probability of exposing a bad . In the agnostic setting there is no with zero population error to anchor against, so the relevant question becomes "how close is to uniformly?" That is a concentration question, answered by Hoeffding: for a single bounded , . The exponent flips from to , and inverting it gives instead of . The square is the unavoidable cost of estimating an unknown mean rather than detecting a single bad consistent hypothesis. See the realizable vs. agnostic comparison for the side-by-side derivation.
Main Theorems
PAC Bound for Finite Hypothesis Classes
Statement
Let be a finite concept class with . In the realizable setting, the ERM algorithm (which outputs any consistent with the training data) satisfies: for any , if the sample size satisfies:
then with probability , the output has .
Intuition
Each "bad" hypothesis (one with error ) has probability at most of being consistent with all training examples. There are at most bad hypotheses. By a union bound, the probability that any bad hypothesis survives is at most . Setting this and solving for gives the bound.
Proof Sketch
The proof is a clean three-step union-bound argument. We give every step explicitly because this template recurs throughout statistical learning theory.
Step 1: Single-hypothesis tail. Fix one hypothesis with . Call bad. For one random example with , the probability that is at most (because disagrees with on at least an fraction of ). Independence across the training points gives:
The convexity inequality for (the tangent line to at ) tightens this to:
Step 2: Union bound over the bad set. Let , with . ERM fails when some bad hypothesis is consistent with (because then ERM may return it). The union bound gives:
The factor of is the price for searching over the whole class. Note it enters additively across hypotheses, which is what allows the logarithm to absorb it in the next step.
Step 3: Solve for . We want the failure probability :
Rearranging gives the sample complexity:
The logarithmic dependence on is the key. A class with hypotheses needs only samples, not . This is what makes ERM tractable even for combinatorially large finite classes. For infinite classes, and this argument fails; VC theory replaces with the VC dimension via symmetrization and the Sauer-Shelah lemma.
Why It Matters
This is the simplest PAC bound and the template for all subsequent results. The sample complexity is . logarithmic in the size of the hypothesis class. This logarithmic dependence is what makes learning from finite classes tractable even when is exponentially large.
Failure Mode
This bound requires the realizable assumption (). In the agnostic case, the rate changes from to . The square is the cost of not knowing the target is in your class.
Fundamental Theorem of PAC Learning
Statement
For binary classification with 0-1 loss, the following are equivalent:
- has finite VC dimension
- is agnostic PAC-learnable
- is PAC-learnable (realizable case)
- ERM over is a successful agnostic PAC learner
Moreover, the sample complexity of agnostic PAC learning is:
and in the realizable case (where some has zero risk):
where is the VC dimension of . The realizable case scales as rather than , the same quadratic- versus-linear gap that appeared in the finite-class bound, now expressed in instead of . The factor in the realizable upper bound is removable for proper realizable learners (Hanneke 2016, JMLR), giving the optimal rate.
Intuition
The VC dimension is the exact measure of hypothesis class complexity that determines learnability. A class is learnable if and only if it cannot shatter arbitrarily large sets of points. The VC dimension replaces the crude of the finite case with a geometric measure of complexity that works for infinite classes.
Why It Matters
This is the most important theorem in statistical learning theory. It completely characterizes PAC learnability: finite VC dimension is both necessary and sufficient. Every other complexity measure (Rademacher complexity, covering numbers, fat-shattering dimension) can be related back to this fundamental characterization.
Failure Mode
This theorem applies only to binary classification with 0-1 loss. For regression, multi-class classification, or other loss functions, the characterization is more complex and involves different complexity measures.
Proof Ideas and Templates Used
The proofs in PAC theory repeatedly use two techniques:
-
Union bound + pointwise concentration: Bound the probability that a single hypothesis is misleading (pointwise), then take a union bound over all hypotheses. This works for finite classes.
-
Symmetrization + growth function: For infinite classes, the union bound over hypotheses is replaced by a union bound over behaviors of hypotheses on a ghost sample. The number of distinct behaviors is bounded by the growth function , which is polynomial in when the VC dimension is finite (Sauer's lemma).
Canonical Examples
Learning conjunctions
The class of conjunctions over Boolean variables contains hypotheses (each variable can appear positive, negative, or absent). The PAC bound gives sample complexity . There is also a simple polynomial-time algorithm: start with all literals and remove any literal falsified by a positive example.
Learning intervals on the real line
The class of intervals has VC dimension 2. By the fundamental theorem, the sample complexity for agnostic PAC learning is , independent of the number of possible intervals (which is uncountably infinite).
Worked Example: Numeric Walkthrough
Take a concrete tier of accuracy targets and compare what the realizable finite-class bound, the VC realizable bound, and the agnostic VC bound actually demand. Fix (a small parametric class such as a 10-dimensional halfspace family with margin), and set throughout.
Realizable finite-class bound (from , with ):
| Sample size | |||
|---|---|---|---|
| 0.10 | 6.93 | 3.00 | 99 |
| 0.05 | 6.93 | 3.00 | 199 |
| 0.01 | 6.93 | 3.00 | 993 |
The bound scales as . Halving doubles the sample requirement.
Agnostic VC bound (from , dropping constants):
| Sample size | ||
|---|---|---|
| 0.10 | 13 | 1300 |
| 0.05 | 13 | 5200 |
| 0.01 | 13 | 130000 |
The agnostic bound scales as . Halving quadruples the sample requirement. At , the agnostic case demands more data than the realizable finite-class bound — the quadratic price of not knowing whether the target is in your class. This factor blows up further as shrinks, which is why agnostic guarantees at very small error tolerances are expensive in practice.
The ratio of agnostic-to-realizable sample complexity is — a ratio that grows as you demand smaller error. At , the agnostic bound is already larger than the realizable bound. This gap is the formal content of the agnostic-vs-realizable comparison.
Lower Bounds: The Bound Is Tight
The upper bounds above are not loose. For binary classification, the agnostic VC sample complexity is tight up to logarithmic factors: there exist matching lower bounds.
Sample-Complexity Lower Bound for VC Classes
Statement
For every PAC learning algorithm and every concept class with , there exist distributions and target concepts on which requires at least
samples to achieve in the agnostic setting, for an absolute constant .
Intuition
The lower bound is constructed by exhibiting a hard distribution: pick shattered points and randomize their labels. Any algorithm with too few samples must miss at least one of the possible labellings, and for that labelling its hypothesis is forced to error . The rate emerges from the variance of empirical-risk estimates on the hard distribution; it cannot be improved without distribution-specific assumptions.
Why It Matters
This says the agnostic PAC sample complexity is tight up to constants and logarithmic factors. You cannot beat in the worst case, no matter what algorithm you design. Any improvement must come from distribution-specific structure (margin, low noise, smoothness) — the content of fast-rate generalization theory.
Failure Mode
The lower bound requires an adversarial distribution. Real data has structure (margin, smoothness, low noise) that allows faster rates. The floor is for the worst-case PAC framework, not for any specific distribution.
The realizable PAC bound has an analogous matching lower bound at , also up to log factors. So the entire PAC framework is essentially complete: VC dimension determines sample complexity, and the bounds are tight.
Connection to Uniform Convergence
The PAC framework and the uniform convergence framework are two sides of the same coin. PAC asks: how many samples does a learner need? Uniform convergence asks: how fast does the empirical risk converge to the true risk uniformly over the hypothesis class? The two are equivalent for binary classification with 0-1 loss.
The bridge: a class is agnostic PAC-learnable if and only if its loss class is a Glivenko-Cantelli class — exactly the classes for which uniformly. ERM is a successful agnostic PAC learner because uniform convergence ensures the empirical-risk minimizer is close to the population-risk minimizer.
For finite classes: uniform convergence follows from a union bound and Hoeffding's inequality. For infinite classes with finite VC dimension: uniform convergence follows from symmetrization plus the Sauer-Shelah polynomial growth bound on the number of distinct hypothesis behaviors on points. Both routes yield the same agnostic rate.
Common Confusions
PAC learnability is distribution-free
The PAC guarantee must hold for every distribution . This is a very strong requirement. It means the sample complexity bounds are worst-case over distributions. For specific, well-behaved distributions, you might need far fewer samples. This is both the strength (universality) and weakness (conservatism) of PAC theory.
Efficient learnability requires polynomial time
PAC learnability as defined above only requires polynomial sample complexity. It says nothing about computational efficiency. A class can be PAC-learnable (finite VC dimension) but not efficiently PAC-learnable (finding the ERM hypothesis is NP-hard). For example, learning intersections of halfspaces is PAC-learnable but believed to be computationally hard.
The realizable assumption is very strong
Assuming means you know the true concept is representable by your hypothesis class. In practice, this is almost never true: real models always face some degree of overfitting. The agnostic setting is more realistic but requires samples instead of . The quadratic cost of agnosticism is a fundamental price you pay for not knowing the true model.
Summary
- PAC = Probably () Approximately () Correct
- Sample complexity for finite class (realizable):
- Sample complexity for finite VC dimension (agnostic):
- The fundamental theorem: finite VC dimension is equivalent to PAC learnability for binary classification
- PAC is distribution-free: bounds hold for the worst-case distribution
- Computational complexity is a separate question from sample complexity
Exercises
Problem
A concept class has 256 concepts. In the realizable setting, how many samples do you need to guarantee that with probability at least , the ERM hypothesis has error at most ?
Problem
Explain in one sentence why the sample complexity for the agnostic case is while the realizable case is .
Problem
The class of all Boolean functions on bits has concepts. What is the PAC sample complexity in the realizable case? Is this class efficiently PAC-learnable?
Related Comparisons
References
Canonical:
- Valiant, "A Theory of the Learnable," Communications of the ACM (1984)
- Shalev-Shwartz & Ben-David, Understanding Machine Learning, Chapters 2-6
- Kearns & Vazirani, An Introduction to Computational Learning Theory (1994), Chapters 1-3
Current:
- Mohri, Rostamizadeh, Talwalkar, Foundations of Machine Learning (2018), Chapter 2
- Wainwright, High-Dimensional Statistics (2019), Chapters 4-6
- Bartlett & Mendelson, "Rademacher and Gaussian Complexities: Risk Bounds and Structural Results," JMLR 3 (2002), 463-482. The Rademacher route to PAC bounds; often tighter than the VC route and the standard reference for data-dependent generalization analysis. jmlr.org
- Hopkins, Kane, Lovett, Mahajan, "Realizable Learning is All You Need," COLT (2022), arXiv:2111.04746 — proves that for any concept class, agnostic learnability is equivalent to realizable learnability up to a polynomial sample-complexity blowup
- Brukhim, Carmon, Dinur, Moran, Yehudayoff, "A Characterization of Multiclass Learnability," FOCS (2022), arXiv:2203.01550 — closes the multiclass case with the DS dimension, settling a 30-year open problem about which multiclass classes are PAC-learnable
Next Topics
The natural next steps from PAC learning:
- Empirical risk minimization: the algorithmic principle that implements PAC learning
- VC dimension: the complexity measure that characterizes PAC learnability
Last reviewed: May 4, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
10- Sets, Functions, and Relationslayer 0A · tier 1
- Concentration Inequalitieslayer 1 · tier 1
- Understanding Machine Learning (Shalev-Shwartz, Ben-David)layer 1 · tier 1
- Hypothesis Classes and Function Spaceslayer 2 · tier 1
- Realizability Assumptionlayer 2 · tier 1
Derived topics
5- VC Dimensionlayer 2 · tier 1
- PAC-Bayes Boundslayer 3 · tier 1
- Bias-Complexity Tradeofflayer 2 · tier 2
- Glivenko-Cantelli Theoremlayer 2 · tier 2
- No-Free-Lunch Theoremlayer 2 · tier 2
Graph-backed continuations