Learning Theory Core
Algorithmic Stability
Algorithmic stability provides generalization bounds by analyzing how much a learning algorithm's output changes when a single training example is replaced: a structurally different lens from complexity-based approaches.
Prerequisites
Why This Matters
The classical approach to generalization, uniform convergence via VC dimension or Rademacher complexity, analyzes the hypothesis class without regard to which algorithm selects a hypothesis from it. This is both a strength (algorithm-independent) and a weakness (cannot explain why specific algorithms generalize better than others on the same class).
Hide overviewShow overview
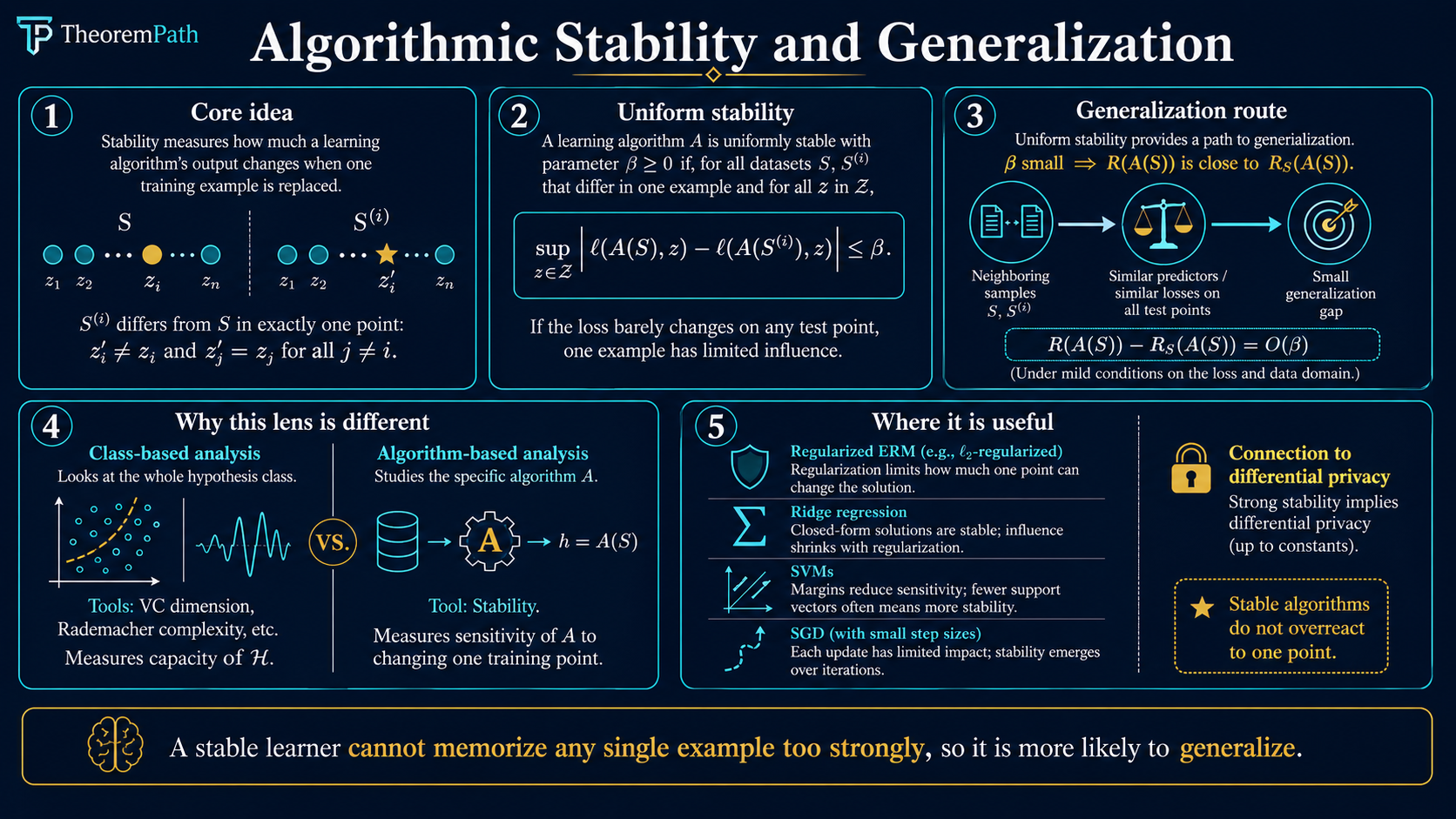
Algorithmic stability takes the opposite approach. It asks: how sensitive is the algorithm's output to perturbations of the training data? If replacing one training example barely changes the learned hypothesis, then the algorithm cannot be overfitting to any particular example, and generalization follows.
This perspective is essential for understanding modern ML: it explains why regularized ERM generalizes, provides the tightest known bounds for many algorithms (SVMs, ridge regression, stochastic gradient descent), and connects to differential privacy.
Mental Model
Imagine running your learning algorithm on a dataset , then replacing one example with a fresh draw from the same distribution. If the resulting hypothesis barely changes, in the sense that its loss on any point changes by at most , then the algorithm is -uniformly stable.
The intuition is: if no single example has too much influence, then the algorithm is not memorizing individual examples, and therefore the training loss is a reliable estimate of the test loss.
Formal Setup and Notation
Let be a (possibly randomized) learning algorithm that takes a training set where drawn i.i.d. from , and outputs a hypothesis .
Let denote the dataset obtained by replacing the -th example with an independent copy drawn from :
Uniform Stability
An algorithm is -uniformly stable (with respect to loss ) if and only if for all datasets of size and all indices :
That is, replacing any single training point changes the loss on any test point by at most .
Hypothesis Stability
A weaker notion: has hypothesis stability if and only if:
This only requires the change to be small on average and at the replaced point. It is weaker than uniform stability but still implies generalization.
Generalization Gap (Stability Perspective)
The expected generalization gap is:
where is the population risk and is the empirical risk. Stability directly controls this quantity.
Main Theorems
Uniform Stability Implies Generalization
Statement
If is -uniformly stable, then the expected generalization gap satisfies:
Moreover, with probability at least over the draw of (two-sided form):
Bousquet and Elisseeff (2002, Theorem 12) state the one-sided version with . The two-sided form above follows by a union bound over the two tails, which replaces with .
Intuition
The expected bound follows from a leave-one-out symmetry argument. By linearity, the expected generalization gap equals the average (over ) of . Since and have the same distribution, swapping them does not change the expectation. Stability means the algorithm barely notices the swap, so the gap is bounded by .
Proof Sketch
Define . We show is small and concentrates.
For the expectation: write and . Since independently, by the symmetry of and . Stability gives , so .
For concentration: replacing with to form changes by at most . The two sources of change are:
- The risk term depends on only through , and -stability implies for any , so .
- The empirical-risk term changes by at most on the unchanged points (again by stability) and by at most on the single replaced point (the loss is bounded by , so its -weighted contribution shifts by at most ).
Adding the two contributions gives the bounded-difference constant . Apply McDiarmid with these bounded differences across the coordinates.
Why It Matters
This theorem gives a completely different path to generalization bounds. Instead of measuring the complexity of , you measure the sensitivity of . For regularized algorithms, often decreases as regularization increases, giving a direct explanation of the regularization-generalization connection.
Failure Mode
Uniform stability requires the worst-case change over all possible datasets and all possible replacement points to be small. Many algorithms (including unregularized ERM over rich classes) are not uniformly stable. The bound is vacuous if is large.
Bousquet-Elisseeff: Regularized ERM is Stable
Statement
Convention. A function is -strongly convex if and only if is convex (equivalently, for twice-differentiable ). Under this convention, is -strongly convex, and is -strongly convex.
If the loss is -Lipschitz in and the regularized ERM objective has a -strongly convex regularizer , then the regularized ERM algorithm is -uniformly stable with:
This matches Bousquet and Elisseeff (2002, Theorem 22) directly. Shalev-Shwartz and Ben-David (2014, Corollary 13.6) use a different convention (calling itself -strongly convex), which yields the equivalent bound with and the regularization weight.
Intuition
Strong convexity means the objective has a unique minimizer, and that minimizer moves continuously (in fact, Lipschitz-continuously) when you perturb the data. Replacing one example out of perturbs the objective by , and the strong convexity constant determines how much the minimizer moves per unit of perturbation. The result is stability .
Proof Sketch
Let and be the minimizers of and the analogous . By optimality:
Adding these, only the two loss terms at index survive; -Lipschitzness of bounds their contribution by . Strong convexity of (inherited from ) at its minimizer gives
and similarly for . Combining yields , so
Lipschitzness of the loss gives . Taking the max over the two sides of the swap (equivalently, using a sharper one-sided argument via first-order optimality conditions) gives the tighter constant stated above. See Bousquet-Elisseeff (2002), proof of Theorem 22, for the argument that avoids the factor-of-4 loss.
Why It Matters
This is the theorem that explains why regularization helps generalization from a stability perspective. For ridge regression (-regularized least squares), the regularizer is -strongly convex, giving stability and therefore a generalization bound of . Combined with the approximation error (which grows with ), you get the classical bias-variance tradeoff derived purely from stability.
Failure Mode
Requires strong convexity of the regularizer and Lipschitzness of the loss. Without regularization (), the bound is vacuous. Non-convex problems (neural networks) are not directly covered, though SGD-specific stability analyses exist.
Bousquet-Elisseeff stability bound β = L²/(2μn) vs sample size n, for L = 1 and three regularization strengths. Below the dashed 5% line the bound is non-vacuous.
The diagram makes the scaling concrete. With fixed, three regularization strengths trace out three decay curves, vertically separated by . The horizontal threshold at marks where the bound becomes operationally non-vacuous: requires to clear it, requires , and requires only . This is the regularization side of the bias-variance tradeoff in raw form: heavier buys stability cheaper in but pays in approximation error not shown here.
The McDiarmid Connection
The high-probability bound in the stability theorem uses McDiarmid's inequality (the bounded differences inequality). The key observation:
If is -uniformly stable, then the generalization gap satisfies a bounded differences condition: replacing any changes by at most
The comes from the change in (stability applied to the test loss), and comes from the direct change in when one of its terms changes.
McDiarmid's inequality then gives: .
Canonical Examples
Ridge Regression
Ridge regression minimizes
The squared loss is -Lipschitz in on the relevant ball when features are bounded (), with effective after a standard a priori bound on . The regularizer is -strongly convex with . Applying the theorem:
With , , : . The expected generalization gap is at most about .
Regularized SVM
The soft-margin SVM with regularization and hinge loss is uniformly stable with (hinge loss is -Lipschitz when , regularizer has , so ). The looser quote also appears in the literature; both forms are correct under different bookkeeping conventions.
Stability theory itself originated earlier with Devroye and Wagner (1979) for -nearest-neighbor and other potential-function rules. SVMs and other regularized convex methods became the headline application in Bousquet and Elisseeff (2002).
SGD Stability (Hardt, Recht, Singer 2016)
Classical Bousquet-Elisseeff covers the exact minimizer of a strongly convex regularized objective. Hardt, Recht, and Singer (2016, arXiv:1509.01240) extend the framework to the iterates of stochastic gradient descent, without assuming a regularizer.
SGD Stability: Smooth Convex Case
Statement
For an -Lipschitz, -smooth, convex loss, SGD with step sizes run for steps is -uniformly stable with:
In particular, steps of constant step size give .
Intuition
The gradient-update map is -expansive when and the loss is convex: replacing one training example and running the same SGD trajectory cannot inflate the iterate gap faster than the single perturbed step introduces. The per-step perturbation is at most with probability (the swap hits the current example). Summing over steps gives the bound.
Why It Matters
Two operational consequences. First, early stopping acts as a regularizer via stability: fewer steps means smaller means tighter generalization bound. Second, long training with constant step size can hurt generalization even if training loss is small: the stability term grows linearly in , so at some point it dominates any training-loss improvement.
Failure Mode
Non-expansivity requires and convexity. Past the smoothness-compatible step size, gradient updates can be expansive and the argument breaks.
For smooth non-convex losses (the realistic deep-learning regime), Hardt-Recht-Singer show that with decaying step size , SGD is uniformly stable with:
where is the smoothness constant. The exponent gives a sub-linear growth in : the bound is non-vacuous for moderate but degrades as grows. This is a formal version of "don't train forever."
SGD stability assumes smoothness, not convexity
A frequent reading error: the non-convex bound is presented without the convex assumption, but smoothness (-Lipschitz gradients) is still required. Non-smooth losses like hinge or ReLU-network losses are not directly covered; extensions exist but require additional assumptions (e.g., subgradient bounds, sampling without replacement analyses).
Differential Privacy Connection
-differential privacy and uniform stability are closely related. Intuitively, DP bounds the distributional effect of swapping one training point on the output distribution; stability bounds its effect on loss values. For loss bounded in , -DP implies uniform stability at scale roughly , which is for small .
Two constructions give stability by design:
- Output perturbation. Train a regularized ERM, add calibrated Gaussian or Laplace noise to the weights. The noise scale gives both the DP guarantee and an explicit stability bound.
- DP-SGD (Abadi et al., 2016, arXiv:1607.00133). Clip per-example gradients to norm , add Gaussian noise to each aggregated minibatch gradient. The moments accountant tracks the cumulative over steps. The same noise that buys privacy also buys stability, and therefore generalization.
This bridge matters for modern ML: when you cannot prove stability directly (non-convex, large models), DP noise offers a constructive path. The price is utility loss proportional to the noise scale.
Convention Equivalence: BE vs SSBD
Two common definitions of stability appear in the literature. They agree up to small constants; the distinction is worth making explicit because papers quote bounds in whichever convention is convenient.
- Bousquet-Elisseeff 2002 (BE). Worst-case, pointwise: .
- Shalev-Shwartz-Ben-David 2014 (SSBD), Chapter 13. In-expectation, replace-one: .
For loss bounded in , BE -uniform stability implies SSBD immediately (expectation of a quantity bounded by is bounded by ). The reverse does not hold in general: in-expectation stability is strictly weaker.
Leave-one-out vs replace-one. Some sources define stability via the leave-one-out dataset of size instead of the replace-one set of size . A one-line algebraic bridge:
Each term on the right is controlled by the replace-one (or leave-one-out) stability at the appropriate sample size. For bounded loss the cost of switching conventions is at most a factor of , and when scales as (the common case) the swap changes the bound by at most , which is negligible next to the leading stability term. PAC-Bayes and stability bounds both target the same generalization quantity via different perturbation models.
Common Confusions
Stability does NOT imply generalization in the converse direction
A common misconception: "if an algorithm generalizes, it must be stable." This is false. There exist algorithms with non-trivial risk guarantees that are not uniformly stable. The classical example is 1-nearest-neighbor: by Cover and Hart (1967), its asymptotic risk is at most twice the Bayes risk, yet it has poor uniform stability because changing one training example can flip predictions in its Voronoi cell. Note that 1-NN is not strongly consistent in general; strong consistency requires -NN with and (Stone, 1977). So "1-NN generalizes" should be read as "has a meaningful risk bound," not "converges to the Bayes classifier."
Stability is sufficient for generalization but not necessary. The relationship is one-directional.
Uniform stability is a strong requirement
Uniform stability requires the loss change to be bounded for every dataset and every test point. This is much stronger than average-case guarantees. Many practical algorithms satisfy weaker notions (hypothesis stability, on-average stability) but not uniform stability. The Bousquet-Elisseeff framework specifically addresses regularized ERM, which is one of the few settings where uniform stability holds cleanly.
Stability bounds and uniform convergence bounds are not competing
Stability bounds and complexity-based bounds (VC, Rademacher) are complementary, not contradictory. They analyze different aspects of learning: complexity bounds measure the class, stability bounds measure the algorithm. For a given algorithm on a given class, one may be tighter than the other. The right tool depends on the situation.
Why Stability Explains Regularized ERM
The Bousquet-Elisseeff theorem gives a clean narrative:
-
Unregularized ERM on a rich class is typically not stable. The minimizer can jump drastically when one example changes, because there are many near-optimal hypotheses.
-
Adding regularization (e.g., ) makes the objective strongly convex, which forces a unique minimizer that varies smoothly with the data.
-
Stronger regularization (larger ) gives better stability () and therefore better generalization, but worse approximation (bias). This is exactly the bias-variance tradeoff.
-
Optimal balances stability (generalization) against approximation error, recovering the classical rate.
Exercises
Problem
Suppose an algorithm is -uniformly stable with . The loss is bounded in . What is the expected generalization gap? Give a high-probability bound with .
Problem
Prove that unregularized ERM over the class of all linear classifiers in (with 0-1 loss) is not uniformly stable. Construct an explicit example where replacing one training point causes the loss on some test point to change by .
Problem
For -regularized logistic regression with regularization parameter , features bounded by , what is the uniform stability parameter? The logistic loss is .
References
Canonical:
- Bousquet & Elisseeff, "Stability and Generalization" (2002), JMLR 2:499-526. Theorems 12 (high-probability bound) and 22 (regularized ERM stability).
- Shalev-Shwartz, Shamir, Srebro, Sridharan, "Learnability, Stability, and Uniform Convergence" (2010), JMLR 11:2635-2670. Shows that in stochastic convex optimization, stability characterizes learnability even in regimes where uniform convergence fails: a counterexample to the equivalence "learnability uniform convergence" that holds for binary classification.
- Shalev-Shwartz & Ben-David, Understanding Machine Learning (2014), Chapter 13 (stability and regularization). Uses the convention where is itself called -strongly convex; bounds therefore appear with different constants than Bousquet-Elisseeff.
- Devroye & Wagner, "Distribution-Free Performance Bounds for Potential Function Rules" (1979), IEEE Trans. IT 25(5):601-604. The earliest stability-style analysis, predating the Bousquet-Elisseeff framework by two decades.
Current:
- Hardt, Recht, Singer, "Train faster, generalize better: Stability of stochastic gradient descent" (2016), ICML; arXiv:1509.01240. Shows that for -Lipschitz, -smooth, convex losses, SGD with step size is uniformly stable with bound after steps; in the strongly convex case the bound becomes dimension-free ; for smooth non-convex losses with , stability is .
- Abadi, Chu, Goodfellow, McMahan, Mironov, Talwar, Zhang, "Deep Learning with Differential Privacy" (2016), CCS; arXiv:1607.00133. Introduces DP-SGD with per-example gradient clipping, Gaussian noise, and the moments accountant. The construction provides -DP and, via the DP-to-stability implication, explicit generalization bounds.
- Boucheron, Lugosi, Massart, Concentration Inequalities (2013), Chapter 6 (McDiarmid's inequality and bounded differences).
Next Topics
The natural next step from algorithmic stability:
- Implicit bias and modern generalization: how stability and implicit regularization explain deep learning
Last reviewed: May 3, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
12- Concentration Inequalitieslayer 1 · tier 1
- Empirical Risk Minimizationlayer 2 · tier 1
- Sample Complexity Boundslayer 2 · tier 1
- VC Dimensionlayer 2 · tier 1
- McDiarmid's Inequalitylayer 3 · tier 1
Derived topics
1- Implicit Bias and Modern Generalizationlayer 4 · tier 1
Graph-backed continuations