LLM Construction
Speculative Decoding and Quantization
Two core inference optimizations: speculative decoding for latency (draft-verify parallelism) and quantization for memory and throughput (reducing weight precision without destroying quality).
Why This Matters
A 70B-parameter model in FP16 requires 140 GB of memory just for the weights. That is more than fits on a single GPU. Even if it fits, autoregressive generation is memory-bandwidth-bound: each token requires reading every weight from memory, and the arithmetic intensity is low.
Hide overviewShow overview
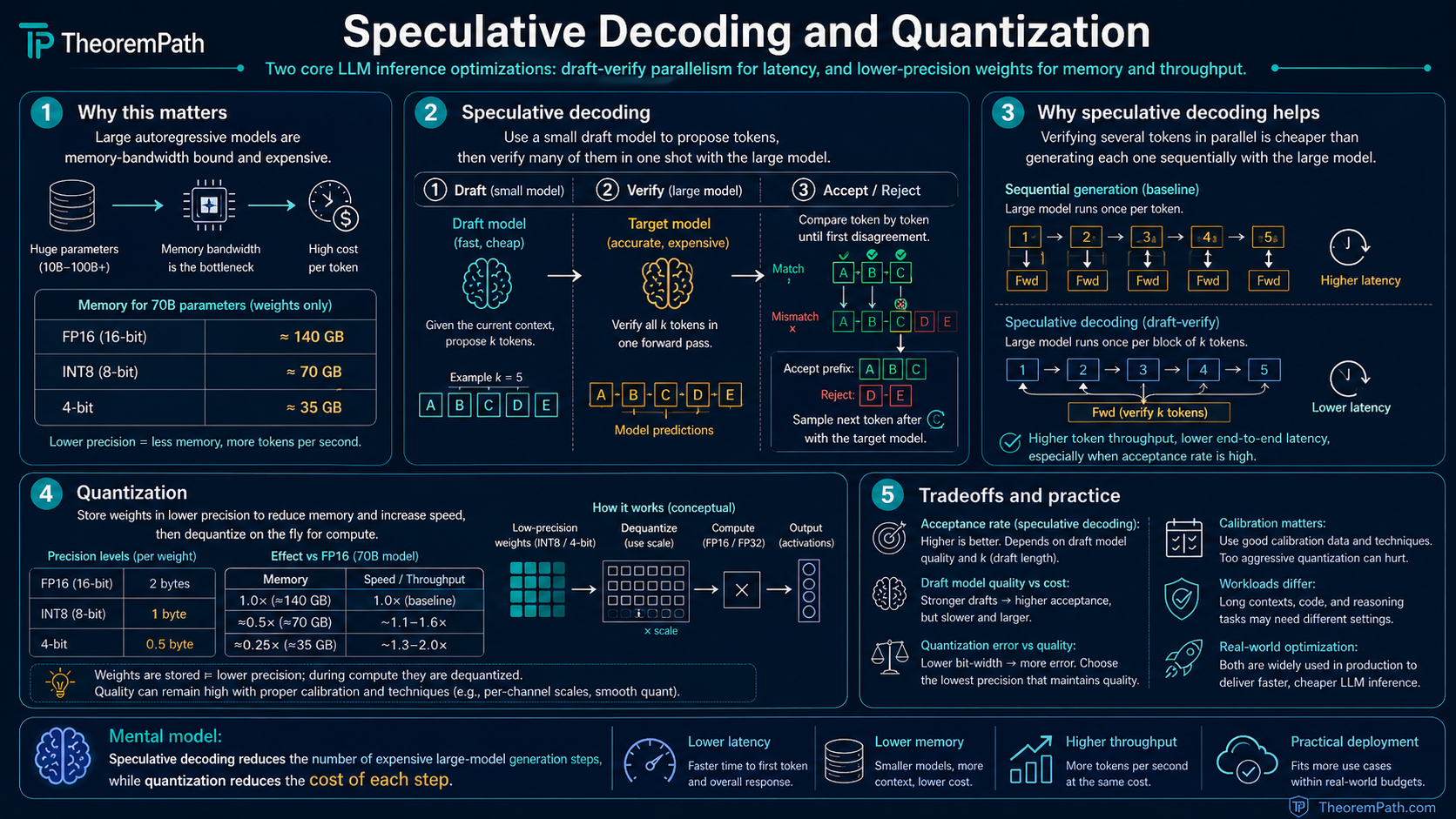
Quantization and speculative decoding are the two techniques with the largest measured speedup for making LLM inference practical. Quantization reduces memory and increases throughput by using lower-precision weights. Speculative decoding reduces latency by generating multiple tokens per large-model forward pass.
These are not optional optimizations. They are how models actually get deployed in production.
Speculative Decoding
Mental Model
Autoregressive generation with a large model is slow because each token requires a full forward pass. The key observation: verifying that a sequence of tokens is correct is much cheaper than generating them one by one, because verification of tokens can be done in a single forward pass (just like processing a prompt).
Speculative decoding exploits this: use a small, fast draft model to propose candidate tokens, then use the large target model to verify them all in one parallel forward pass. Accept the tokens that the target model agrees with; reject and resample from the point of disagreement.
Speculative Decoding
Speculative decoding uses a draft model (small, fast) and a target model (large, accurate). At each step:
- The draft model generates candidate tokens autoregressively
- The target model computes for all tokens in a single forward pass
- Each token is accepted or rejected using a modified rejection sampling scheme
- Generation continues from the first rejected position (or past all if all accepted)
The Correctness Guarantee
Speculative Decoding Preserves Target Distribution
Statement
The speculative decoding algorithm with modified rejection sampling produces tokens distributed exactly according to the target model , regardless of the quality of the draft model . Specifically, at each position, the accepted token satisfies:
The draft model affects only the speed (expected number of accepted tokens per verification step), not the distribution of the output.
Intuition
The acceptance criterion is: accept draft token with probability . If proposes a token that also likes (), it is always accepted. If proposes a token that dislikes (), it is accepted with probability . On rejection, resample from the residual distribution normalized. This is standard rejection sampling. The output distribution is exactly .
Why It Matters
This is the key theoretical property: speculative decoding is not an approximation. It produces exactly the same distribution as the target model. You get speed for free with zero quality degradation. The draft model is purely a proposal mechanism. a bad draft model just means fewer tokens are accepted per step, not that the output quality changes.
Failure Mode
The guarantee requires exact probability computation. In practice, numerical precision differences between draft and target models can cause slight distributional deviations. Also, the speedup depends on the acceptance rate: if the draft model is very different from the target, most tokens are rejected and the overhead of running the draft model is wasted. The draft model must be a reasonable approximation of the target for practical speedups.
Speedup Analysis
Let denote the acceptance probability at draft position . A key bookkeeping point: the target model always contributes one additional token per verification step. If all draft tokens are accepted, the target's next-token distribution yields a bonus token in the same forward pass. If the first rejection occurs at position , the residual distribution resamples one target-model token at that position. Either way, one target sample is guaranteed per step.
Accounting for this guaranteed token, the expected tokens generated per verification step is:
In the i.i.d. case where each , the geometric sum collapses:
This matches Leviathan, Kalman, and Matias (2023, arXiv:2211.17192). If the draft model closely matches the target (high ), the expected number of tokens approaches . In practice, speculative decoding with a 10x smaller draft model achieves 2-3x speedup on typical text generation tasks.
Quantization
Mental Model
Neural network weights are typically stored in FP16 (16-bit floating point) or BF16. Quantization maps these to lower precision. INT8 (8-bit integer), INT4 (4-bit), or even lower. Fewer bits means less memory, faster memory reads, and often specialized hardware support for low-precision arithmetic.
The challenge: quantization introduces error. The question is whether this error matters for the task you care about.
Post-Training Quantization (PTQ)
PTQ quantizes a pretrained model without retraining. Given a weight tensor , quantize to bits via:
where is a learned or calibrated scale factor. PTQ is fast (minutes to hours on a calibration dataset) but introduces quantization noise that is not compensated by training.
Quantization-Aware Training (QAT)
QAT simulates quantization during training using the straight-through estimator: the forward pass uses quantized weights, but gradients are computed as if the rounding did not occur. This allows the model to adapt its weights to be robust to quantization noise. QAT produces better results than PTQ but requires a full training run.
Quantization Error
Per-Layer Quantization Error
Statement
For a weight matrix quantized to bits with step size , the per-element quantization error satisfies two distinct bounds:
The worst-case bound assumes adversarial rounding. The MSE expression assumes the residual is uniformly distributed on , which is the standard Bennett quantization-noise model. Both scale as : halving the precision roughly quadruples the error per weight.
Intuition
Quantization maps each weight to the nearest representable value. The maximum rounding error is half the step size . Under the Bennett model (uniform residuals), the expected squared error of a single rounding is the variance of , which is . The step size is set by the dynamic range of the weights divided by the number of quantization levels (). Wider dynamic range or fewer bits means larger steps and more error.
Why It Matters
This explains why outlier weights are so problematic: a single large weight forces a large scale factor , increasing quantization error for all weights in that channel. This is why methods like LLM.int8() isolate outlier channels and quantize them separately, and why per-channel quantization outperforms per-tensor quantization.
Failure Mode
The per-element MSE bound does not capture the downstream effect on model quality. Some weights are more important than others: quantization error in attention projection weights affects the model differently than error in FFN weights. Methods like GPTQ and AWQ use Hessian information to minimize the effect of quantization on the output (not just the weights themselves).
Symmetric vs Asymmetric Quantization
The definition above is symmetric: the quantization grid is centered at zero and a single scale factor maps real values to integers. Asymmetric (affine) quantization adds a zero-point offset so that with . The zero-point lets the integer grid align with an arbitrary real-valued interval , which is strictly more expressive for distributions with nonzero mean (typical of activations and many post-LayerNorm weights).
Symmetric is simpler (no zero-point arithmetic, faster kernels) and is common for weights. Most production LLM INT8 and INT4 pipelines use asymmetric quantization for activations, and many use asymmetric for weights as well to avoid wasting half the integer range when the weight distribution is skewed. GPTQ, AWQ, and GGUF all expose asymmetric modes.
Group-Wise Quantization Overhead
For fine-grained INT4 quantization, weights are typically partitioned into groups of size (commonly ) along the input dimension, with one scale factor (and optionally one zero-point) per group. This tames outlier sensitivity but costs extra memory for the scales. If scales are stored in FP16, the extra memory is
For a 70B-parameter model at with FP16 scales, this adds roughly GB of scale data, which is small relative to the INT4 payload (35 GB) but not negligible. If zero-points are also stored in FP16, double that. Smaller improves accuracy but grows the scale overhead linearly.
Quantization Methods in Practice
GPTQ (Generative Pre-Trained Transformer Quantization): Applies layer-wise quantization using approximate second-order information (the Hessian of the layer output with respect to the weights). Quantizes weights one column at a time, updating remaining columns to compensate for the quantization error of each column. Achieves good INT4 results.
AWQ (Activation-Aware Weight Quantization): Identifies "salient" weight channels (those multiplied by large activations on calibration data) and protects them by scaling before quantization. Simple and effective.
GGUF: A file format (not a quantization method) for storing quantized models, widely used in local inference (llama.cpp). Supports mixed-precision quantization: different layers can use different bit-widths.
Combining Both Techniques
Speculative decoding and quantization compose cleanly because they attack different bottlenecks: quantization reduces memory-bandwidth cost per token, speculative decoding amortizes that cost across multiple accepted tokens per forward pass. A typical production pipeline:
- Quantize the target model to INT8 or FP8 (sometimes INT4) to fit in available GPU memory and raise throughput
- Keep the small draft model in FP16 (or a light quantization) so draft generation stays fast and the acceptance rate does not degrade
- Serve with speculative verification to reduce latency
A common production choice is INT8 or FP8 target with FP16 draft. Quantizing the draft too aggressively hurts acceptance rate, which eats into the speculative speedup. Richer draft strategies such as Medusa (Cai et al. 2024, arXiv:2401.10774), EAGLE (Li et al. 2024, arXiv:2401.15077), and Lookahead Decoding (Fu et al. 2024) replace the external draft model with multi-head self-drafting or n-gram lookahead, which pairs well with a quantized target.
For inference, start with INT8 quantization (AWQ or GPTQ). This halves memory with minimal quality loss and is the lowest-risk optimization. For latency- sensitive applications, add speculative decoding with a draft model that is roughly 10x smaller than the target. Only go to INT4 if memory is the binding constraint, and validate on your specific eval suite because INT4 can degrade rare-token generation and calibration.
Quantization does not just "make things smaller." It introduces specific distributional errors that disproportionately affect: (1) outlier weights and activations, (2) calibration (confidence estimates become unreliable before accuracy degrades), (3) rare-token generation (low-frequency tokens have less gradient signal during QAT and suffer more from PTQ rounding). A model that "looks fine" on perplexity benchmarks may have degraded tail behavior that matters for your application.
Common Confusions
Speculative decoding is not approximate
A common misunderstanding is that speculative decoding trades quality for speed. It does not. The output distribution is mathematically identical to sampling from the target model. The speedup comes from parallelizing verification, not from approximating the distribution.
INT4 is not half as good as INT8
The relationship between bit-width and quality is nonlinear and task-dependent. INT8 post-training quantization is nearly lossless for most models. INT4 PTQ introduces measurable degradation but is often acceptable. Post-training INT3 and INT2 are generally destructive. The transition from "fine" to "broken" tends to be sharp rather than gradual at the post-training extreme.
This is a statement about post-training quantization. Training-time low-bit schemes tell a different story: BitNet b1.58 (Ma et al. 2024, arXiv:2402.17764) trains with ternary weights in and reports quality competitive with FP16 baselines at scale. The lesson is that extreme quantization is a training-recipe problem, not a pure numerical-precision problem. If you start from an FP16 checkpoint and round to INT2, quality collapses; if you train from scratch with quantization-aware objectives, ternary is viable.
Summary
- Speculative decoding: draft model proposes, target model verifies in parallel. Output distribution is exactly the target model's distribution.
- Speedup depends on draft-target agreement; typically 2-3x for a 10x smaller draft model
- Quantization: reduce weight precision from FP16 to INT8/INT4 to save memory and increase throughput
- PTQ is fast but noisy; QAT is expensive but robust
- Outlier weights are the main challenge. per-channel scaling and Hessian-aware methods address this
- Start with INT8 quantization; add speculative decoding for latency; go to INT4 only if memory is the bottleneck
Exercises
Problem
A 70B-parameter model in FP16 requires 140 GB of memory. How much memory does it require after INT8 quantization? After INT4?
Problem
In speculative decoding, suppose the draft model's per-token acceptance rate is and you generate draft tokens per step. What is the expected number of tokens accepted per verification step? What if ?
Problem
Quantization-aware training uses the straight-through estimator (STE): the forward pass uses quantized weights , but the backward pass computes gradients as if (ignoring the rounding). Why does this biased gradient estimator work in practice? When might it fail?
Related Comparisons
References
Canonical (speculative decoding):
- Leviathan, Kalman, Matias, "Fast Inference from Transformers via Speculative Decoding" (ICML 2023, arXiv:2211.17192). Original algorithm, correctness proof, and expected-tokens-per-step formula .
- Chen, Borgeaud, et al., "Accelerating Large Language Model Decoding with Speculative Sampling" (2023, arXiv:2302.01318). Concurrent DeepMind version.
Current (speculative decoding variants):
- Cai et al., "Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads" (2024, arXiv:2401.10774). Multi-head self-drafting, no separate draft model.
- Li et al., "EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty" (2024, arXiv:2401.15077). Feature-level drafting, higher acceptance rates.
- Fu et al., "Break the Sequential Dependency of LLM Inference Using Lookahead Decoding" (2024). Jacobi-iteration-style drafting with n-gram cache.
Canonical (quantization):
- Frantar et al., "GPTQ: Accurate Post-Training Quantization for Generative Pre-Trained Transformers" (ICLR 2023). Hessian-aware column-wise PTQ, chapter on error-compensation.
- Lin et al., "AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration" (MLSys 2024). Salient-channel scaling.
- Dettmers et al., "LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale" (NeurIPS 2022). Outlier-channel decomposition.
Current (quantization and mixed precision):
- Dettmers et al., "QLoRA: Efficient Finetuning of Quantized LLMs" (2023, arXiv:2305.14314). 4-bit NormalFloat storage plus low-rank adapters for finetuning.
- Xiao et al., "SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models" (ICML 2023, arXiv:2211.10438). Activation-weight scale migration.
- Micikevicius et al., "FP8 Formats for Deep Learning" (2022, arXiv:2209.05433). E4M3 and E5M2 FP8 training and inference standard.
- Ma et al., "The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits" (2024, arXiv:2402.17764). Training-time ternary weights at LLM scale.
Next Topics
The natural next steps from speculative decoding and quantization:
- Context engineering: designing the full inference pipeline around these efficiency constraints
- Mixture of experts: another approach to efficiency that MoE models themselves need quantization and speculative decoding to serve
Last reviewed: April 18, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
4- Transformer Architecturelayer 4 · tier 2
- KV Cachelayer 5 · tier 2
- Multi-Token Predictionlayer 5 · tier 2
- Megakernelslayer 5 · tier 3
Derived topics
4- Mixture of Expertslayer 4 · tier 2
- Context Engineeringlayer 5 · tier 2
- Edge and On-Device MLlayer 5 · tier 2
- Inference Systems Overviewlayer 5 · tier 2
Graph-backed continuations