LLM Construction
Edge and On-Device ML
Running models on phones, embedded devices, and edge servers: pruning, distillation, quantization, TinyML, and hardware-aware neural architecture search under memory, compute, and power constraints.
Prerequisites
Why This Matters
Not every ML workload can go to the cloud. Running models on-device provides four advantages that cloud inference cannot match: latency (no network round trip), privacy (data never leaves the device), cost (no per-query API fees), and availability (works offline). The constraint is that edge devices have limited memory (1-8 GB on phones, kilobytes on microcontrollers), limited compute (mobile GPUs or CPUs), and strict power budgets.
Hide overviewShow overview
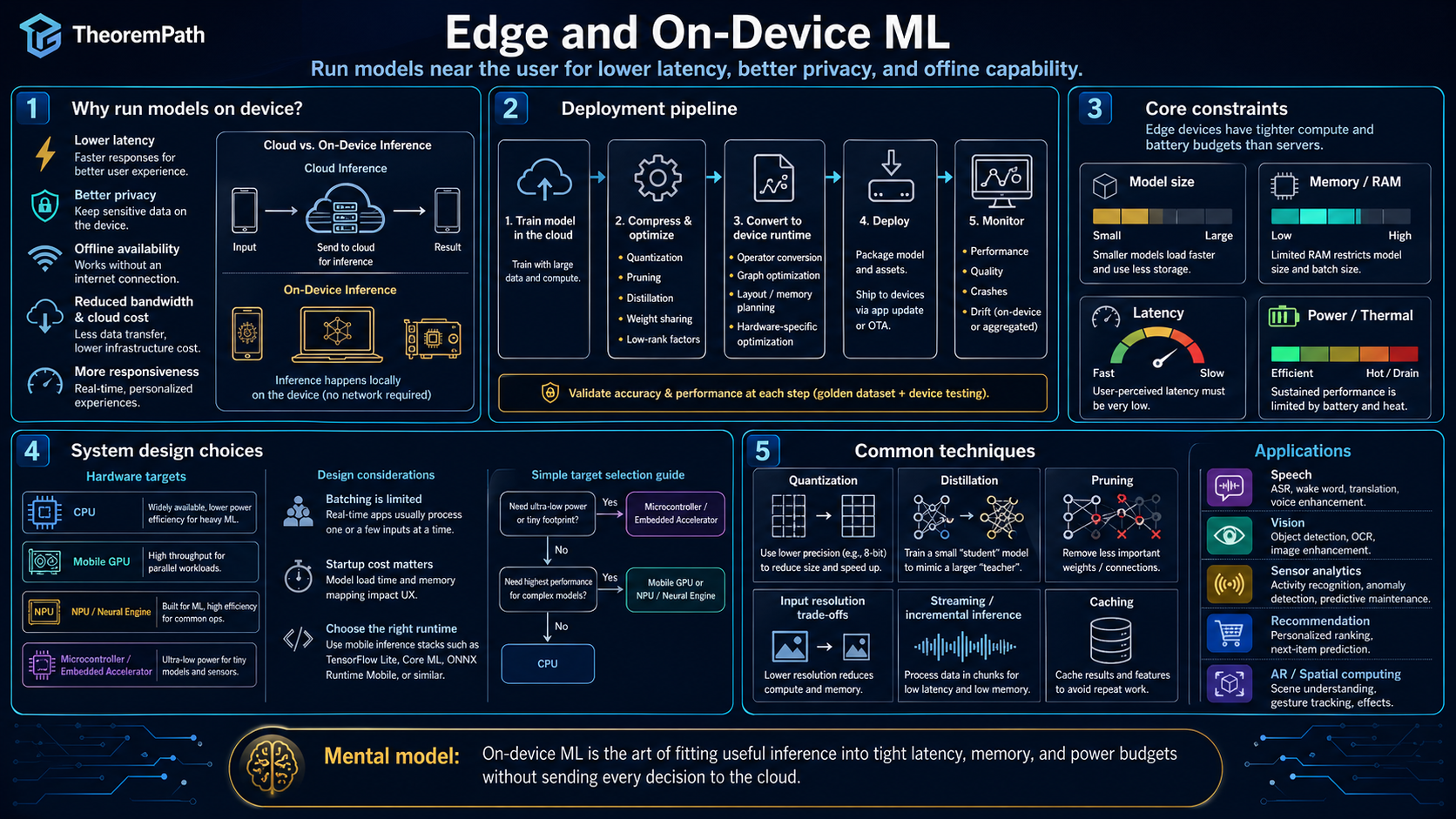
Deploying a model on-device requires compressing it. sometimes by 10-100x. This is not just quantization. It includes pruning (removing weights), distillation (training a small model from a large one), and architecture search (finding architectures that are efficient on target hardware).
Mental Model
Think of edge deployment as fitting a large piece of furniture through a narrow doorway. You have three options: cut pieces off (pruning), build a smaller replica (distillation), or redesign the furniture for the doorway (architecture search). In practice, you use all three.
Model Compression Techniques
Pruning
Pruning removes weights or entire structures (neurons, attention heads, layers) from a trained model. Unstructured pruning zeros individual weights, producing a sparse weight matrix. Structured pruning removes entire rows, columns, or blocks, producing a smaller dense matrix. Structured pruning is more hardware-friendly because dense operations are faster than sparse ones on most accelerators.
Knowledge Distillation
Knowledge distillation trains a small student model to mimic the outputs of a large teacher model. The student is trained on the teacher's soft probability distributions (logits) rather than hard labels. The distillation loss for input is:
where and are teacher and student logits, is softmax, and is the temperature. The factor is the standard Hinton 2015 Section 2.1 rescaling: the gradient of the softened KL with respect to student logits scales as , so multiplying the loss by keeps gradient magnitudes comparable across temperatures. Higher temperature softens the distributions, lifting tail probabilities out of numerical underflow.
Hardware-Aware Neural Architecture Search (NAS)
Hardware-aware NAS searches over neural architectures while directly optimizing for latency, memory, or energy on the target hardware. The search objective is typically:
where parameterizes the architecture. Latency is measured (or predicted via a lookup table) on the actual target device, not estimated from FLOPs alone. FLOPs are a poor proxy for latency because memory bandwidth, parallelism, and operator support vary across hardware.
Why Pruning Works: The Lottery Ticket Observation
Empirically, dense randomly initialized networks contain sparse subnetworks that, when trained in isolation from the same initialization, match the full network's accuracy. Frankle and Carbin (2019) called this the lottery ticket hypothesis. It is an empirical observation, not a theorem: the original evidence comes from experiments on small vision networks, and the finding requires iterative magnitude pruning with weight rewinding to an initialization or early training iterate. See model compression and pruning for the full treatment and scope conditions.
For edge deployment, the practical takeaway is narrower: trained networks are routinely prunable to 50-90% sparsity with small accuracy loss. This supports pruning as a compression step but does not by itself guarantee a prunable winning subnetwork for a given architecture or pretraining setup.
A Provable Quantization Bound
Uniform Quantization Mean-Squared Error
Statement
Let be a uniform -bit quantizer with levels and step size . Under the high-rate assumption that the quantization error is uniform on , the mean-squared quantization error per weight is:
Each additional bit reduces the MSE by a factor of 4, i.e., by 6.02 dB in signal-to-quantization-noise ratio.
Intuition
A uniform distribution on has variance . Each extra bit halves , which squares into a factor of four in MSE. This "6 dB per bit" rule is the textbook baseline for PCM quantization and sets a floor on post-training quantization error before calibration or rounding improvements.
Proof Sketch
For ,
Substituting gives the stated bound. See Gray and Neuhoff (1998), "Quantization," IEEE Trans. Info. Theory, for the high-rate derivation and the precise regularity conditions under which the uniform error model applies.
Why It Matters
This bound is the starting point for any post-training quantization analysis on edge devices. Given a target MSE per weight, it tells you the minimum bit-width required. Real schemes (GPTQ, AWQ, SmoothQuant) improve on this by shaping weight distributions and rounding, but the baseline is the reference against which improvements are measured.
Failure Mode
The uniform-error model breaks when weights cluster near quantizer boundaries or when the dynamic range is set by a few outliers. Activation quantization in transformers is a notorious case: a small number of outlier channels inflate , driving up and thus MSE. Per-channel quantization, clipping, or outlier-aware calibration is needed in practice. The bound also assumes scalar quantization per weight; vector quantization can beat it by exploiting correlations.
Pruning in Practice
Magnitude pruning: remove weights with the smallest absolute values. Simple and effective. Typically achieves 50-90% sparsity with minimal accuracy loss on CNNs and moderate-sized transformers.
Movement pruning: remove weights that move toward zero during fine-tuning, regardless of their magnitude. Better than magnitude pruning for pretrained language models because large pretrained weights may not be relevant to the downstream task.
Structured vs. unstructured: unstructured pruning (zero out individual weights) achieves higher sparsity ratios but requires sparse matrix support from the hardware. Structured pruning (remove entire heads, layers, or channels) produces dense models that run fast on any hardware but achieves lower sparsity ratios.
TinyML
TinyML targets microcontrollers with kilobytes of memory and milliwatts of power. Typical constraints:
- RAM: 256 KB to 1 MB
- Flash: 1-4 MB (for model storage)
- Compute: ARM Cortex-M cores, no GPU, no floating-point unit
At this scale, even INT8 quantization may be insufficient. Models use INT4 or binary weights. Architectures are designed from scratch for the constraint envelope: MobileNets, MCUNet, and similar designs.
The key insight: for edge deployment on microcontrollers, the model must fit entirely in SRAM during inference. There is no virtual memory, no swap, no disk-backed storage. If the model does not fit, it does not run.
Distillation Dynamics
The temperature parameter in distillation controls the information transfer:
- : standard softmax. The student sees the teacher's hard predictions (nearly one-hot for confident predictions).
- : softened distributions. Higher temperature compresses the ratio between any two class probabilities toward 1 (), but it lifts tail probabilities out of numerical underflow so the student can see them at all. If the teacher's logits give and at (ratio 10), at both probabilities rise into a visible range and the ratio shrinks toward . The "dark knowledge" the student learns is not the original ratio but the presence of secondary structure that was invisible at .
- Large : distributions become nearly uniform, washing out useful information.
The optimal temperature is task-dependent and typically found by grid search. Common values are .
FLOPs do not predict on-device latency
A model with fewer FLOPs is not necessarily faster on a specific device. Memory-bound operations (large matrix reads with few arithmetic operations) may dominate latency. Depthwise convolutions have few FLOPs but poor hardware utilization on GPUs. Always benchmark on the target device rather than comparing FLOP counts.
Distillation is not just training on teacher labels
Training a student on the teacher's hard labels (argmax predictions) is not distillation. The value of distillation comes from the soft probability distributions, which encode the teacher's uncertainty and inter-class similarity structure. This "dark knowledge" in the non-predicted class probabilities is what makes distillation more effective than training on hard labels alone.
Summary
- Edge deployment requires model compression: pruning, distillation, quantization, and architecture design
- Pruning removes unimportant weights; the lottery ticket hypothesis explains why this works
- Distillation transfers knowledge from a large teacher to a small student via soft probability distributions at temperature
- Hardware-aware NAS optimizes architecture for actual device latency, not FLOPs
- TinyML targets microcontrollers with KB-scale memory; models must fit entirely in SRAM
- FLOPs are a poor proxy for on-device latency; always benchmark on target hardware
Exercises
Problem
A model has 100M parameters in FP32 (4 bytes each). The target device has 50 MB of available memory. Can the model fit? If not, what compression ratio do you need, and name two techniques that could achieve it.
Problem
A teacher model achieves 95% accuracy on a classification task with 100 classes. You distill into a student that achieves 90% accuracy when trained with hard labels. Using distillation with , accuracy increases to 93%. Explain the mechanism by which the soft labels help, using a concrete example with class probabilities.
Problem
The lottery ticket hypothesis requires iterative magnitude pruning with weight rewinding, which costs multiple full training runs. Propose a method to find winning tickets in a single training run. What assumptions would your method need?
References
Canonical:
- Frankle & Carbin, "The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks" (ICLR 2019). Iterative magnitude pruning with weight rewinding on small vision networks; see also Frankle-Dziugaite-Roy-Carbin 2020 Linear Mode Connectivity arXiv:1912.05671 for the late-rewinding clarification.
- Hinton, Vinyals, Dean, "Distilling the Knowledge in a Neural Network" (2015), Section 2.1. Soft-target KL loss with gradient-magnitude rescaling.
- Han, Mao, Dally, "Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding" (ICLR 2016). Canonical combined pruning + quantization + entropy-coding pipeline.
- Gray & Neuhoff, "Quantization" (IEEE Trans. Inf. Theory, 1998). High-rate derivation of the bound.
Current:
- Lin et al., "MCUNet: Tiny Deep Learning on IoT Devices" (NeurIPS 2020)
- Howard et al., "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications" (2017)
- Xiao, Lin, Seznec, Wu, Demouth, Han, "SmoothQuant: Accurate and Efficient Post-Training Quantization for LLMs" (ICML 2023)
- Frantar, Ashkboos, Hoefler, Alistarh, "GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers" (ICLR 2023)
- Dettmers, Pagnoni, Holtzman, Zettlemoyer, "QLoRA: Efficient Finetuning of Quantized LLMs" (NeurIPS 2023)
- On-device LLM runtimes: llama.cpp (Gerganov, ongoing), MLC-LLM (Chen et al., ongoing), Apple Foundation Models (Apple 2024), Gemini Nano (Google 2024), Microsoft Phi series (Abdin et al. 2024 arXiv:2404.14219).
Next Topics
The natural next steps from edge and on-device ML:
- Inference systems overview: the full stack for serving models, from cloud to edge
Last reviewed: April 13, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
1- Speculative Decoding and Quantizationlayer 5 · tier 2
Derived topics
1- Inference Systems Overviewlayer 5 · tier 2
Graph-backed continuations