LLM Construction
Post-Training Overview
How post-training turns a pretrained language model into a deployable assistant: SFT, preference optimization, safety tuning, verifiable rewards, evaluation gates, and the failure modes each stage introduces.
Prerequisites
Why This Matters
Hide overviewShow overview
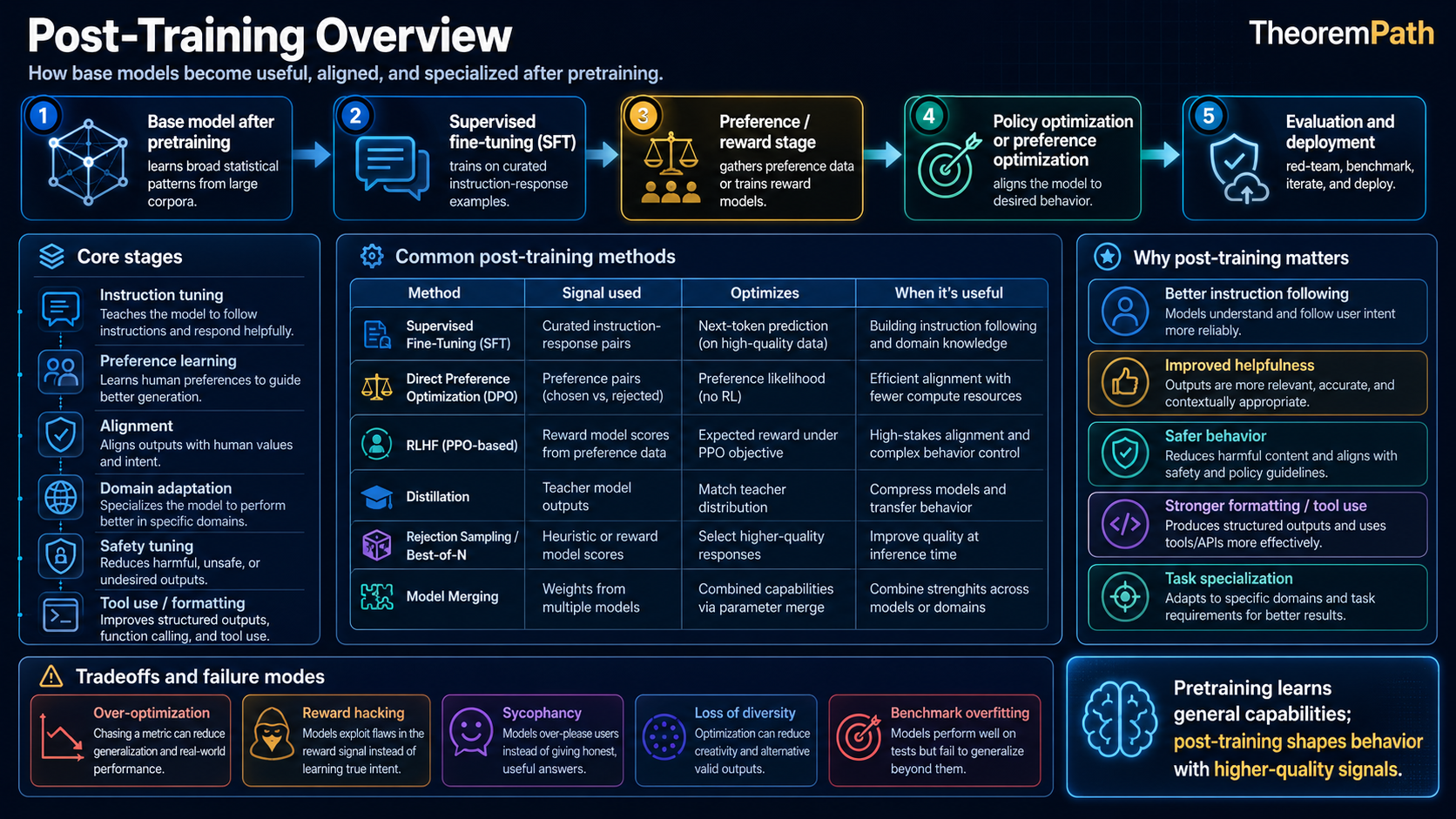
A pretrained language model is a next-token predictor. A deployed assistant is a policy with formatting habits, refusal behavior, tool-use conventions, safety boundaries, and release gates. Post-training is where many of those behaviors are specified, tested, and revised.
The exact recipe differs by lab and model. Public reports increasingly describe some mix of supervised fine-tuning, preference optimization, safety tuning, verifiable-reward training, and evaluation-driven iteration. The point is not that every system uses the same pipeline; it is that model behavior after pretraining is shaped by a stack of separate control signals.
Mental Model
Think of post-training as a series of increasingly precise shaping operations:
- Pretraining gives you raw material: a model that knows language but has no concept of "helpfulness" or "safety."
- SFT teaches the format: how to respond to instructions, when to refuse.
- Preference optimization (RLHF, DPO, GRPO) teaches the style: which responses are better than others.
- Safety training teaches the boundaries: what not to do.
- Verifier-guided training teaches reasoning: how to produce correct answers, not just fluent ones.
- Self-improvement loops teach the model to improve itself using its own outputs as training signal.
Each stage has different objectives, different data requirements, and different failure modes. Understanding the full pipeline is necessary for understanding why modern assistants behave the way they do.
The Post-Training Pipeline
Post-Training Pipeline
The post-training pipeline is the sequence of training stages applied after pretraining to transform a base language model into a deployable assistant. A common public recipe as of April 2026 looks like:
Each arrow represents a distinct training stage with its own data, loss function, and optimization procedure.
Stage 1: Supervised Fine-Tuning (SFT)
SFT trains the model on high-quality (instruction, response) pairs using standard next-token prediction:
This teaches the model format: how to follow instructions, use markdown, cite sources, refuse harmful requests. It does not by itself teach quality. A model trained only with SFT will follow instructions but often produce average responses drawn from the demonstration distribution.
SFT as Forward-KL Minimization (Identity)
Statement
This is an algebraic identity, not a substantive theorem. The expected SFT loss decomposes into the entropy of the data distribution plus the forward KL from data to model:
Since does not depend on , minimizing the SFT loss is equivalent to minimizing . This is the standard cross-entropy to KL decomposition (Cover and Thomas, Chapter 2, Section 2.3). Forward KL is mode-covering: it penalizes assigning low probability to any point where has mass.
Intuition
SFT tries to match the distribution of training responses. This means the model learns to produce average responses that cover the range of the training data. It does not learn to produce the best responses. This is why SFT alone produces adequate but rarely excellent outputs.
Why It Matters
The mode-covering property of forward KL explains why SFT models are often "bland". They hedge across the full range of training responses rather than committing to the best one. Preference optimization addresses this by pushing the model toward the preferred modes.
Stage 2: Preference and Reward Optimization
After SFT, the model is trained against preference data, learned reward models, or task-specific reward signals. The main families in current public reports:
- RLHF: train a reward model on preferences, then optimize with PPO
- DPO: directly optimize on preference pairs without a separate reward model
- GRPO: group relative policy optimization, often used with rule-based or verifiable rewards in reasoning-oriented training
Each is easiest to understand as a way to change the policy while keeping it near a reference model. See the DPO vs GRPO vs RL reasoning page for detailed comparison.
Selected Methods
- KTO (Kahneman-Tversky Optimization, Ethayarajh et al. 2024): treats alignment as an unpaired binary-feedback problem and optimizes a prospect-theoretic utility instead of a Bradley-Terry pairwise likelihood. Avoids the need for matched (chosen, rejected) pairs, which are expensive to collect at scale.
- RLAIF (RL from AI Feedback, Lee et al. 2023): replaces human preference labelers with a capable AI judge. Scales preference data generation at the cost of importing the judge's biases and calibration errors into the reward signal.
- Tulu 3 (Lambert et al. 2024): a fully open post-training recipe combining SFT, DPO, and RL with verifiable rewards (RLVR) on tasks with ground-truth checks such as math and code.
- Iterative / online DPO (Xu et al. 2024, "Iterative Preference Learning"): interleaves on-policy sampling, preference labeling, and DPO updates instead of running DPO once on a fixed offline dataset, which narrows the distribution-shift gap between reference and trained policies.
Conceptual Decomposition of Post-Training Gaps
This is a conceptual decomposition for organizing post-training techniques, not a formal theorem. The target distribution is underspecified and the decomposition is not a tight identity without additional assumptions. Treat it as an engineering taxonomy.
Informally, the gap between the deployed policy and some notional ideal can be organized into three main contributions:
- Pretrain coverage gap: the base model assigns little or no mass to behaviors the ideal policy requires (format, refusals, tool-use patterns). SFT addresses this by shifting support onto demonstrated behaviors.
- Alignment and instruction gap: even after SFT, the model produces average-quality completions rather than the preferred modes. Preference optimization (RLHF, DPO, KTO, GRPO) targets this gap.
- Preference-elicitation gap: preference data itself is noisy, sycophancy prone, and mis-specified for reasoning tasks. Safety training, constitutional methods, and verifier-guided RL exist because preference signals do not faithfully reveal .
These gaps interact. Reducing one can increase another: safety training can reduce helpfulness, reasoning training can increase verbosity, preference optimization can amplify sycophancy. The pipeline structure reflects this multi-objective reality, not a closed-form error bound.
Stage 3: Safety Training
Safety training prevents the model from producing harmful outputs. Methods:
- Constitutional AI: the model critiques and revises its own outputs against a set of principles, generating synthetic preference data
- Red-teaming: adversarial prompts reveal failure modes, which become training data for the next round
- Rule-based reward models (RBRMs): classifier-based reward signals for specific safety categories (toxicity, PII, dangerous instructions)
The key tension: safety training and helpfulness training compete. A model that refuses nearly everything may reduce some categories of risk while becoming useless. A model that answers everything is helpful in the short term but unsafe under adversarial or high-stakes use. Deployment decisions live on this helpfulness-safety frontier.
Stage 4: Verifier-Guided Training
For reasoning tasks (math, code, logic), human preferences can be unreliable: even expert humans may not consistently judge whether a long chain of reasoning is correct under time pressure. Verifiers help by checking outputs against an explicit criterion:
- Code execution: run the code and check if it passes tests
- Math verification: check against ground truth or use formal provers
- Fact-checking: verify claims against a knowledge base
The model is then trained with RL using verifier feedback as the reward signal. Published systems such as DeepSeek-R1 and open recipes such as Tulu 3 make this verifiable-reward stage explicit for domains where checks are available.
Stage 5: Self-Improvement Loops
The least settled stage: the model generates candidate training data, filters it with a verifier or evaluator, and then trains on the selected outputs.
- Generate many candidate solutions to a problem
- Use a verifier to select the correct ones
- Train on the correct solutions (rejection sampling fine-tuning)
- Repeat with the improved model
This is a form of iterative distillation where the model distills its own best-case behavior into its average-case behavior. The risk is distribution collapse. The model becomes increasingly narrow in its outputs.
"RLHF = alignment." RLHF makes the model produce outputs that score highly on a reward model trained on human preferences. This is not the same as alignment. A sycophantic model that tells users what they want to hear scores highly on preference data. A model that confidently confabulates scores higher than one that hedges honestly. RLHF optimizes for human approval, which correlates with but is not identical to truthfulness, safety, or genuine helpfulness. The broader post-training pipeline, including safety training, constitutional AI, and verifier-guided RL, exists because RLHF alone is insufficient.
The open reports are useful because they expose the moving parts. Llama 3.1 describes a detailed post-training stack, Tulu 3 releases an open recipe with SFT, DPO, and RLVR, and DeepSeek-R1 reports RL that incentivizes reasoning on verifiable tasks. These reports do not imply a universal recipe, but they do show why "fine-tuning" is now too vague: deployed behavior is the product of several data sources, objectives, and evaluation gates.
Common Confusions
Post-training is not just fine-tuning
Traditional fine-tuning adjusts a pretrained model on task-specific data. Modern post-training is a multi-stage pipeline with distinct objectives at each stage. Calling post-training "fine-tuning" obscures the complexity: SFT, preference optimization, safety training, and verifier-guided RL are structurally different training procedures with different data requirements and failure modes.
More post-training stages is not always better
Each additional stage risks degrading performance on earlier objectives. Safety training can make the model less helpful (over-refusal). Reasoning training can make the model verbose on simple questions. The pipeline must be carefully calibrated, and regressions on earlier stages must be monitored throughout.
SFT data quality matters more than quantity
A small dataset of expert-written responses often outperforms a large dataset of crowdsourced responses. The LIMA paper (2023) showed that 1,000 carefully curated examples can produce strong SFT results. The quality of SFT data determines the starting point for all subsequent stages.
Summary
- Post-training pipeline: pretrain SFT preference optimization safety/evaluation verifier-guided RL where checks exist
- SFT teaches format (forward KL minimization, mode-covering)
- Preference optimization teaches quality (RLHF, DPO, or GRPO)
- Safety training teaches boundaries (constitutional AI, red-teaming, RBRMs)
- Verifier-guided RL teaches reasoning (code execution, math provers)
- Self-improvement loops use the model's own correct outputs as training data
- Each stage can degrade performance on earlier objectives; calibration is critical
- RLHF alone is not alignment. The full pipeline is the alignment attempt
Exercises
Problem
Explain why SFT alone is insufficient for producing a high-quality assistant. What specific failure mode does preference optimization address that SFT cannot?
Problem
The safety-helpfulness tradeoff can be modeled as a constrained optimization problem. Formalize this: write the objective (maximize helpfulness) and the constraint (maintain safety above a threshold), and explain why Lagrangian relaxation converts this into a weighted sum that maps onto the RLHF framework.
Problem
Self-improvement loops (generate, verify, retrain) can suffer from distribution collapse. Formalize this risk: if the model generates solutions from and retrains on verified correct solutions, what happens to the entropy over iterations? Under what conditions does the model converge to a useful fixed point versus a degenerate one?
References
Canonical:
- Ouyang et al., "Training Language Models to Follow Instructions with Human Feedback" (InstructGPT), NeurIPS 2022; arXiv:2203.02155.
- Bai et al. (Anthropic), "Constitutional AI: Harmlessness from AI Feedback" (2022); arXiv:2212.08073.
- Rafailov, Sharma, Mitchell, Ermon, Manning, Finn, "Direct Preference Optimization: Your Language Model is Secretly a Reward Model", NeurIPS 2023; arXiv:2305.18290. Derivation of the DPO objective from KL-regularized preference RL.
- Ethayarajh, Xu, Muennighoff, Jurafsky, Kiela, "KTO: Model Alignment as Prospect Theoretic Optimization" (2024); arXiv:2402.01306. Unpaired preference optimization using a Kahneman-Tversky utility.
- Lee et al., "RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback" (2023); arXiv:2309.00267. Replaces human labelers with an AI judge for scalable preference data.
- Xu et al., "Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint" (2024); arXiv:2404.10719. Online / iterative DPO to reduce off-policy distribution shift.
- Shao et al., "DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models" (2024); arXiv:2402.03300. Introduces Group Relative Policy Optimization (GRPO), which drops the value network and estimates advantages from group-relative rewards.
Current pipeline and reasoning RL:
- Dubey et al., "The Llama 3 Herd of Models" (2024); arXiv:2407.21783. Detailed multi-stage post-training pipeline in a frontier release.
- DeepSeek-AI, "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning" (2025); arXiv:2501.12948. Verifier-guided RL with GRPO.
- Lambert et al., "Tulu 3: Pushing Frontiers in Open Language Model Post-Training" (2024); arXiv:2411.15124. Open SFT to DPO to RLVR recipe with verifiable rewards.
- Zhou et al., "LIMA: Less Is More for Alignment", NeurIPS 2023; arXiv:2305.11206. Evidence that SFT data quality dominates quantity.
Critiques and limits of RLHF as alignment:
- Casper et al., "Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback" (2023); arXiv:2307.15217. Reward hacking, distributional shift, and evaluator bias.
- Perez et al., "Discovering Language Model Behaviors with Model-Written Evaluations" (2022); arXiv:2212.09251. Sycophancy and other emergent RLHF failure modes.
Next Topics
The natural next steps from post-training:
- DPO vs GRPO vs RL reasoning: detailed comparison of preference optimization methods
- Reward models and verifiers: the training signals that drive post-training
- Test-time compute and search: what happens at inference after post-training
Last reviewed: April 22, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
6- Policy Optimization: PPO and TRPOlayer 3 · tier 2
- BERT and the Pretrain-Finetune Paradigmlayer 4 · tier 2
- RLHF and Alignmentlayer 4 · tier 2
- Transformer Architecturelayer 4 · tier 2
- Agentic RL and Tool Uselayer 5 · tier 2
Derived topics
5- DPO vs GRPO vs RL for Reasoninglayer 5 · tier 2
- GPT Series Evolutionlayer 5 · tier 2
- LLaMA and Open Weight Modelslayer 5 · tier 2
- Reasoning Data Curationlayer 5 · tier 2
- Reward Models and Verifierslayer 5 · tier 2