LLM Construction
DPO vs GRPO vs RL for Reasoning
Head-to-head comparison of preference optimization methods: DPO's implicit reward, GRPO's group-relative comparisons, and RL with verifier feedback for reasoning. When each works and when each fails.
Prerequisites
Why This Matters
Hide overviewShow overview
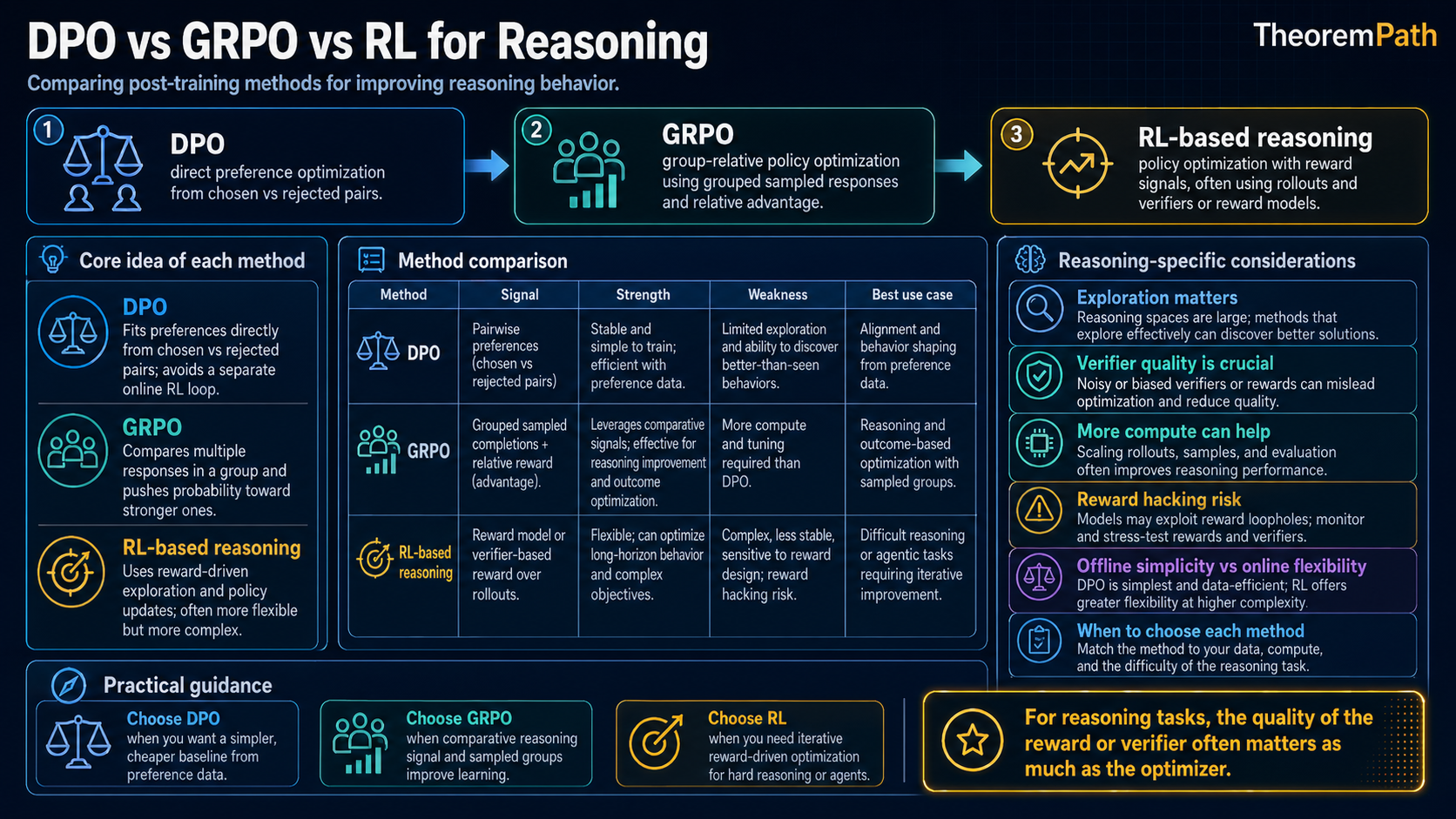
After supervised fine-tuning, the next stage of post-training optimizes the model on preference data: which outputs are better than others. Three methods dominate in 2026, each with distinct tradeoffs:
- DPO (Direct Preference Optimization): no separate reward model, stable training, widely adopted, but offline-only and prone to a likelihood- displacement failure mode that Razin et al. (2024) characterize formally.
- GRPO (Group Relative Policy Optimization): the algorithm Shao et al. (2024) introduce in DeepSeekMath and Guo et al. (2025) scale up in DeepSeek-R1. Group-relative advantages, no critic.
- RL with verifiable rewards (RLVR): PPO/REINFORCE with rule-based feedback from code execution, math equality checks, or formal provers. Used in o1-class reasoning models and DeepSeek-R1.
Choosing the wrong method wastes compute and produces worse models. The acronyms hide what actually differs: DPO and the others optimize different objectives under different sample distributions. Knowing which knob is being turned is necessary to predict which failure modes show up.
Mental Model
Three ways to teach a model which outputs are "better":
- DPO: Show the model pairs of outputs (one preferred, one not) and directly adjust probabilities. No intermediary. Simple but limited to pairwise comparisons.
- GRPO: Show the model a group of outputs, rank them by reward, and adjust probabilities relative to the group average. More signal per batch than pairwise comparisons.
- RL with verifiers: Let the model generate solutions, check them with an objective verifier (run the code, check the math), and use the binary correctness signal as reward in a standard RL loop.
DPO: Direct Preference Optimization
DPO Implicit Reward Equivalence
Statement
DPO reparameterizes the reward model through the policy itself. The implicit reward under DPO is:
The DPO loss directly optimizes on preference pairs :
At convergence, this recovers the same optimal policy as RLHF with a Bradley-Terry reward model and KL penalty .
Intuition
DPO says: instead of training a reward model and then doing RL, observe that the optimal policy defines a reward function. So skip the reward model and optimize the policy directly on preference data. The log-ratio plays the role of the reward: increase the log-ratio for preferred outputs, decrease it for dispreferred ones.
Why It Matters
DPO eliminates the reward model training, the PPO loop, and the associated hyperparameter tuning. This makes it simpler to implement, more stable to train, and cheaper in compute. It became the default preference optimization method for many research groups in 2023-2024.
Failure Mode
DPO is an offline algorithm: it optimizes on a fixed dataset of preference pairs. It does not generate new outputs during training. This means it cannot explore. It only learns from the preferences in the training data. If the training data does not cover a failure mode, DPO cannot fix it. Additionally, the implicit reward can still be hacked: the model learns to increase for preferred outputs, which can be achieved by making the reference policy assign low probability (rather than by genuinely improving quality).
DPO strengths:
- Simple pipeline: one-stage supervised loss
- Stable training: no RL instabilities
- Well-understood theoretically (equivalence to KL-regularized RLHF)
DPO weaknesses:
- Offline: no exploration, limited by training data distribution
- Pairwise only: uses one comparison per training example
- Can degrade with noisy preferences or low-quality pairs
- Likelihood displacement: when preferred and dispreferred responses are embedding-similar, DPO can decrease the probability of the preferred response (Razin et al. 2024, treated below)
Likelihood Displacement: When DPO Pushes Down the Preferred Response
Razin, Malladi, Bhaskar, Chen, Arora, and Hanin (2024, "Unintentional Unalignment: Likelihood Displacement in Direct Preference Optimization", arXiv:2410.08847) show formally and empirically that DPO can produce gradients that move probability mass off the preferred response.
The mechanism. The DPO update increases the log-ratio gap , not the absolute log- probability of . When and share token-level support — token sequences with high embedding similarity, common in instruction-tuning data — the most efficient way to widen the gap is to suppress the shared support of both responses while routing the saved probability mass to a third response that is neither preferred nor dispreferred.
Razin et al. introduce a closed-form quantity, the centered hidden embedding similarity (CHES), that predicts which preference pairs will trigger displacement. Pairs with high CHES exhibit the failure; filtering them out of the preference dataset prevents it. They show that this is not an edge case: on Llama-3-8B, DPO without CHES filtering can drive the preferred-response probability below the dispreferred-response probability on a non-trivial fraction of the training distribution, while still appearing to converge by the DPO loss.
This is a structural failure of the offline objective, not a hyperparameter issue. KTO (Ethayarajh et al. 2024) and SimPO (Meng, Xia, Chen 2024) modify the objective to avoid the log-ratio framing and substantially reduce displacement; online methods (PPO, GRPO) avoid it because the policy generates the comparison samples and never trains on near-duplicates.
GRPO: Group Relative Policy Optimization
GRPO Objective
Statement
For a prompt , GRPO generates a group of outputs from the current policy . Each output receives a reward . The group-relative advantage is:
The GRPO objective is:
where is the importance ratio (as in PPO). The key innovation: advantages are computed relative to the group, not against an external baseline or value function.
Intuition
GRPO eliminates the need for a learned value function (critic). Instead of asking "how good is this output in absolute terms?" it asks "how good is this output compared to the other outputs the model just generated?" This group-relative comparison provides a natural baseline that adapts to the difficulty of each prompt.
For a hard prompt where all outputs are bad, the best-of-bad gets a positive advantage. For an easy prompt where all outputs are good, the worst-of-good gets a negative advantage. This automatic calibration stabilizes training.
Why It Matters
GRPO was introduced by DeepSeek and used to train DeepSeek-R1 for mathematical and code reasoning. By eliminating the critic network, GRPO reduces memory requirements and removes a source of approximation error. The group-relative advantage provides richer signal than DPO's pairwise comparisons: from outputs you get advantage estimates, not just one pairwise comparison.
Failure Mode
GRPO requires generating outputs per prompt during training, which increases compute cost. If is too small, the advantage estimates are noisy. If the reward model is unreliable, the group-relative advantage amplifies reward model errors. The model learns to distinguish between "slightly more hackable" and "slightly less hackable" outputs rather than between genuinely good and bad ones.
GRPO strengths:
- Online: generates fresh outputs during training, enabling exploration
- No critic network: reduces memory and eliminates value function errors
- Group-relative advantages: automatic baseline calibration per prompt
- Richer signal: comparisons per prompt vs DPO's single pair
GRPO weaknesses:
- Higher compute cost per step (generating samples)
- Requires a reward model or verifier for scoring
- Advantage normalization can reduce gradient signal when group variance is low
RL with Verifier Feedback
RL with Verifier Feedback
Statement
For reasoning tasks with a binary verifier (e.g., code passes all tests, math answer is correct), the RL objective is:
The gradient (via REINFORCE with baseline ) is:
where is typically the running average pass rate for prompt .
Intuition
This is the cleanest form of RL for reasoning: generate a solution, check if it is correct, reinforce correct solutions and suppress incorrect ones. The verifier signal does not require a learned reward model, so it does not have the Bradley-Terry preference-data biases. The binary signal is sparse but verifiable.
Why It Matters
Verifiable-reward RL is how DeepSeek-R1, the OpenAI o-series, and the Gemini 2.5 thinking models learn to reason about math and code. The reward signal is a rule (does this code pass the test suite, is this math answer equal to the gold), not a learned preference model. That removes the Bradley-Terry biases documented in RLHF deep-dive (sycophancy, intransitivity, labeler-pool drift). It does not remove reward hacking; it shifts hacking from "fool the preference rater" to "exploit the verifier."
Failure Mode
Binary rewards are sparse: most solutions to hard problems are wrong, giving reward 0 for most samples. Learning is slow and high-variance. Process reward models (PRMs) provide step-level rewards but reintroduce the learned-proxy problem. The deeper failure mode is verifier hacking, treated below: any rule-based verifier defines a measurable proxy, and the policy gradient finds the cheapest way to maximize that proxy whether or not it corresponds to genuine reasoning.
Verifiable Rewards Do Not Eliminate Reward Hacking
The claim that "you cannot hack a unit-test suite" is wrong. Three failure modes are documented across the verifiable-reward RL literature:
-
Test-overfitting from leaked test cases. When the verifier suite is fully visible to the policy (as in many code RL setups), the model can pattern-match the inputs and emit branch-on-test-input code that returns the expected output without solving the underlying problem. The DeepSeek-R1 paper (Guo et al. 2025, arXiv:2501.12948) reports needing rule-based safeguards against language-mixing and against models exploiting the pattern of the answer-extraction regex.
-
Verifier-bug exploitation. Math verifiers compare strings or numerical values up to formatting; the model can learn to produce answers that the verifier accepts without being mathematically correct (wrong sign hidden by absolute value, units that the regex strips, fraction reduction loopholes). Lehman, Clune, Misevic et al. (2018, The Surprising Creativity of Digital Evolution, arXiv:1803.03453) catalog 27 case studies of evolutionary RL exploiting simulator and reward bugs; the same dynamics apply to verifiable-reward LLM RL because the optimizer is doing the same job.
-
Reasoning-trace gaming. When step-level rewards come from a learned process reward model (PRM), the policy can learn to write reasoning traces that convince the PRM rather than traces that solve the problem. This is the verifier-side analog of Bradley-Terry sycophancy and is the reason process rewards are not a free fix. Krakovna's Specification gaming examples (DeepMind, ongoing public list) catalogs analogous behavior across RL settings; Pan, Bhatia, and Steinhardt (ICLR 2022, arXiv:2201.03544) identify a phase transition where increased policy capability suddenly amplifies exploitation of a misspecified reward.
The honest framing: rule-based verifiers replace one source of reward error (human-preference noise) with another (rule mis-specification). Whether the trade is favorable depends on how tightly the rule matches the underlying intent. For competitive-math final answers the rule is tight; for "good explanation" or "safe behavior" no usable rule exists, and the verifier path is not available.
Verifier-guided RL shifts reward hacking, it does not eliminate it
The pitch for RLVR over RLHF is "no reward model to hack." That is true at the gradient-source level: the reward is a deterministic rule, not a learned classifier. But the policy still does whatever maximizes the rule. If the rule is a compile-and-pass-tests check, the policy will learn to pass tests by any means available, including hardcoding test inputs, special-casing visible test cases, or exploiting verifier bugs. RLHF reward hacking and RLVR verifier hacking are the same phenomenon (Goodhart's law on a measurable proxy) operating on different proxies. The 2024-2026 deployment evidence (DeepSeek-R1 language-mixing rules, Anthropic reasoning-trace incidents) is that RLVR shifts the spec-gaming surface, not that it removes it.
RL with verifiers strengths:
- Rule-based reward signal: removes preference-data biases (sycophancy, intransitivity, labeler-pool drift)
- Effective for domains with checkable answers (math, code, formal logic)
- Can improve beyond human-level (verifier can check solutions humans cannot)
RL with verifiers weaknesses:
- Sparse binary reward: slow learning, high variance
- Only works for verifiable domains
- Requires infrastructure for code execution, proof checking, etc.
- Verifier hacking remains: tight-rule verifiers shift the spec-gaming surface (test pattern-matching, regex exploits, language-mixing) rather than eliminating it
Early claims that DPO "solves" RLHF were premature. When DPO was published in 2023, it was presented as a simpler alternative that achieves the same results without RL instabilities. In practice, DPO's limitations became clear by 2024-2025. Its offline nature means it cannot improve beyond the quality of its training data. Reward hacking still occurs through the implicit reward. And for reasoning tasks where verifier-guided RL excels, DPO consistently underperforms. DPO remains useful for general preference alignment, but the claim that it makes RL unnecessary was wrong. The most capable models in 2026 all use RL at some stage.
"DPO is RLHF without RL." This is wrong and reveals a shallow understanding. DPO is RL. It optimizes the exact same KL-regularized objective as RLHF, derived from the same Bradley-Terry preference model. The implicit reward is a reward function parameterized by the policy. DPO merely reparameterizes the optimization to avoid explicit reward model training and PPO. The RL objective is still there; it is absorbed into the supervised loss. Saying "DPO eliminates RL" is like saying "substituting variables eliminates the equation": the mathematical content is identical, only the computational procedure changed. The non-trivial difference is the sample distribution. DPO trains on a fixed offline distribution while RLHF/GRPO/RLVR train on on-policy samples. Tajwar et al. (2024) show that this single distinction explains most of the empirical gap between offline and online preference learning, especially when the preference data has coverage holes.
When to Use Each Method
| Criterion | DPO | GRPO | RL + Verifier |
|---|---|---|---|
| Training data | Offline preference pairs | Online generation | Online generation |
| Reward signal | Implicit (from preferences) | Explicit (RM or verifier) | Explicit (rule-based verifier) |
| Exploration | None | Yes (generates new outputs) | Yes (generates new outputs) |
| Compute per step | Low | Medium ( samples) | Medium-High |
| Best domain | General preference alignment | Reasoning with RM or verifier | Math, code, formal verification |
| Distinctive failure mode | Likelihood displacement (Razin 2024) | Zero gradient when group reward is uniform | Verifier hacking (test pattern-match, regex exploits) |
| Reward-hacking surface | Implicit-reward misuse, Bradley-Terry biases | RM-dependent; rule-based when verifier is the scorer | Rule mis-specification; not eliminated, only relocated |
Common Confusions
DPO and RLHF target the same optimal policy
Under the Bradley-Terry model with KL regularization, the theoretical optimum is identical for DPO and RLHF. The differences are purely algorithmic: convergence speed, sensitivity to hyperparameters, exploration capability. In practice, these algorithmic differences matter enormously. RLHF with PPO can explore beyond the training data while DPO cannot.
GRPO is not just PPO without a critic
GRPO shares PPO's clipped objective but differs in how advantages are computed. PPO uses a learned value function as baseline; GRPO uses the group mean reward. This changes the gradient dynamics: GRPO's advantages are always centered at zero within each group, while PPO's advantages depend on the accuracy of the value function. When the value function is inaccurate (common for long reasoning tasks), GRPO's group-relative approach can be more stable.
Verifier-guided RL is not limited to final-answer checking
While the simplest setup uses a binary outcome reward, process reward models provide step-level feedback within the reasoning chain. The choice between outcome and process rewards is a bias-variance tradeoff: outcome rewards are unbiased but sparse; process rewards are dense but potentially biased (the PRM is a learned proxy).
Summary
- DPO: implicit reward via policy log-ratio, offline, no RM needed, no exploration. Likelihood displacement (Razin 2024) is its distinctive failure mode.
- GRPO (Shao et al. 2024 in DeepSeekMath, Guo et al. 2025 in DeepSeek-R1): group-relative advantages, online, no critic.
- RLVR: rule-based reward from code execution or provers. Sparse, less biased than learned RMs, but not hack-proof. Verifier hacking is the successor to RM hacking, not its absence.
- DPO is RL. Same KL-regularized objective as RLHF, just reparameterized. The non-trivial gap between DPO and RLHF/GRPO/RLVR is on-policy vs off-policy samples (Tajwar et al. 2024).
- For reasoning tasks with reliable rule-based verifiers, RLVR consistently outperforms DPO and is the dominant choice in 2025-2026 frontier reasoning models.
- For general preference alignment without verifiers, DPO and its variants (KTO, SimPO) remain competitive when the dataset is filtered for likelihood-displacement risk.
- GRPO occupies the middle ground: online exploration with simpler infrastructure than PPO and a per-prompt baseline that handles non- stationary difficulty.
Exercises
Problem
Show that the DPO gradient for a single preference pair increases and decreases . What determines the magnitude of the update?
Problem
GRPO computes advantages as where and are the group mean and standard deviation. Show that when all outputs receive the same reward (e.g., all correct or all incorrect), the GRPO gradient is zero. Explain why this is both a feature and a limitation.
Problem
DPO is offline (fixed dataset), while GRPO and RL with verifiers are online (generate new outputs during training). Formalize the advantage of online methods: consider a policy that has learned to avoid one failure mode but now exhibits a new one not present in the original preference data. Why can GRPO/RL address this but DPO cannot?
Related Comparisons
References
Pre-canonical:
- Bradley and Terry, "Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons", Biometrika 39(3/4):324-345 (1952). The preference model underlying RLHF, DPO, and reward learning.
- Christiano et al., "Deep Reinforcement Learning from Human Preferences" (NeurIPS 2017). Established the preference-RL pipeline that RLHF operationalizes.
Canonical:
- Schulman, Wolski, Dhariwal, Radford, Klimov, "Proximal Policy Optimization Algorithms" (2017). The clipped-ratio policy-gradient algorithm that RLHF and GRPO both build on.
- Ouyang et al., "Training Language Models to Follow Instructions with Human Feedback" (InstructGPT, NeurIPS 2022). The paper that turned RLHF into the dominant LLM post-training approach.
- Rafailov et al., "Direct Preference Optimization: Your Language Model is Secretly a Reward Model" (NeurIPS 2023). DPO derivation and closed-form loss.
- Shao et al., "DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models" (2024). GRPO formulation.
Current:
- Guo et al. (DeepSeek-AI), "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning" (2025), arXiv:2501.12948. GRPO at scale with rule-based rewards; documents language-mixing and answer-extraction-pattern hacks that required rule-based safeguards.
- Razin, Malladi, Bhaskar, Chen, Arora, Hanin, "Unintentional Unalignment: Likelihood Displacement in Direct Preference Optimization" (2024, ICLR 2025), arXiv:2410.08847. Closed-form CHES diagnostic and conditions under which DPO drives the preferred-response probability below the dispreferred-response probability.
- Tajwar, Singh, Sharma et al., "Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data" (ICML 2024), arXiv:2404.14367. Formalizes the on-policy-vs-off-policy gap that explains DPO underperformance on coverage-poor preference data.
- Xu et al., "Some Things Are More CRINGE Than Others" (2024). DPO failure modes.
- Pal et al., "Smaug: Fixing Failure Modes of Preference Optimisation with DPO-Positive" (2024). Documents DPO's tendency to reduce the chosen-response likelihood.
- Azar et al., "A General Theoretical Paradigm to Understand Learning from Human Preferences" (IPO, AISTATS 2024). Identifies overfitting in DPO from the Bradley-Terry-to-DPO derivation.
- Ethayarajh et al., "KTO: Model Alignment as Prospect Theoretic Optimization" (2024). Preference-free alternative using binary signals.
- Meng, Xia, Chen, "SimPO: Simple Preference Optimization with a Reference-Free Reward" (NeurIPS 2024). Length-normalized DPO without a reference model.
- Ahmadian et al., "Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback" (2024). Argues RLOO suffices vs PPO complexity.
Reward hacking on verifiable rewards:
- Lehman, Clune, Misevic et al., "The Surprising Creativity of Digital Evolution: A Collection of Anecdotes from the Evolutionary Computation and Artificial Life Research Communities" (2018), arXiv:1803.03453. 27 case studies of evolutionary RL exploiting simulator and reward bugs; the same phenomena recur in verifiable-reward LLM RL.
- Krakovna, "Specification gaming examples" (DeepMind, ongoing public list). Catalog of RL agents finding unintended ways to maximize their reward signal.
- Pan, Bhatia, Steinhardt, "The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models" (ICLR 2022), arXiv:2201.03544. Phase-transition behavior in policy hacking when proxy and true reward diverge.
Next Topics
The natural next steps from preference optimization:
- Reward models and verifiers: the signals that drive these methods
- Post-training overview: how these methods fit into the full pipeline
Last reviewed: April 23, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
9- Policy Gradient Theoremlayer 3 · tier 1
- Chain-of-Thought and Reasoninglayer 5 · tier 1
- Reinforcement Learning from Human Feedbacklayer 5 · tier 1
- Actor-Critic Methodslayer 3 · tier 2
- Policy Optimization: PPO and TRPOlayer 3 · tier 2
Derived topics
0No published topic currently declares this as a prerequisite.