LLM Construction
PaddleOCR and Practical OCR
A practitioner's guide to modern OCR toolkits: PaddleOCR's three-stage pipeline, TrOCR's transformer approach, EasyOCR, and Tesseract. When to use which, and what accuracy to expect.
Why This Matters
OCR is the entry point for most document intelligence pipelines. Before you can extract structured information from a document, you need to convert pixel regions into text strings. The choice of OCR engine determines the quality ceiling for everything downstream.
Hide overviewShow overview
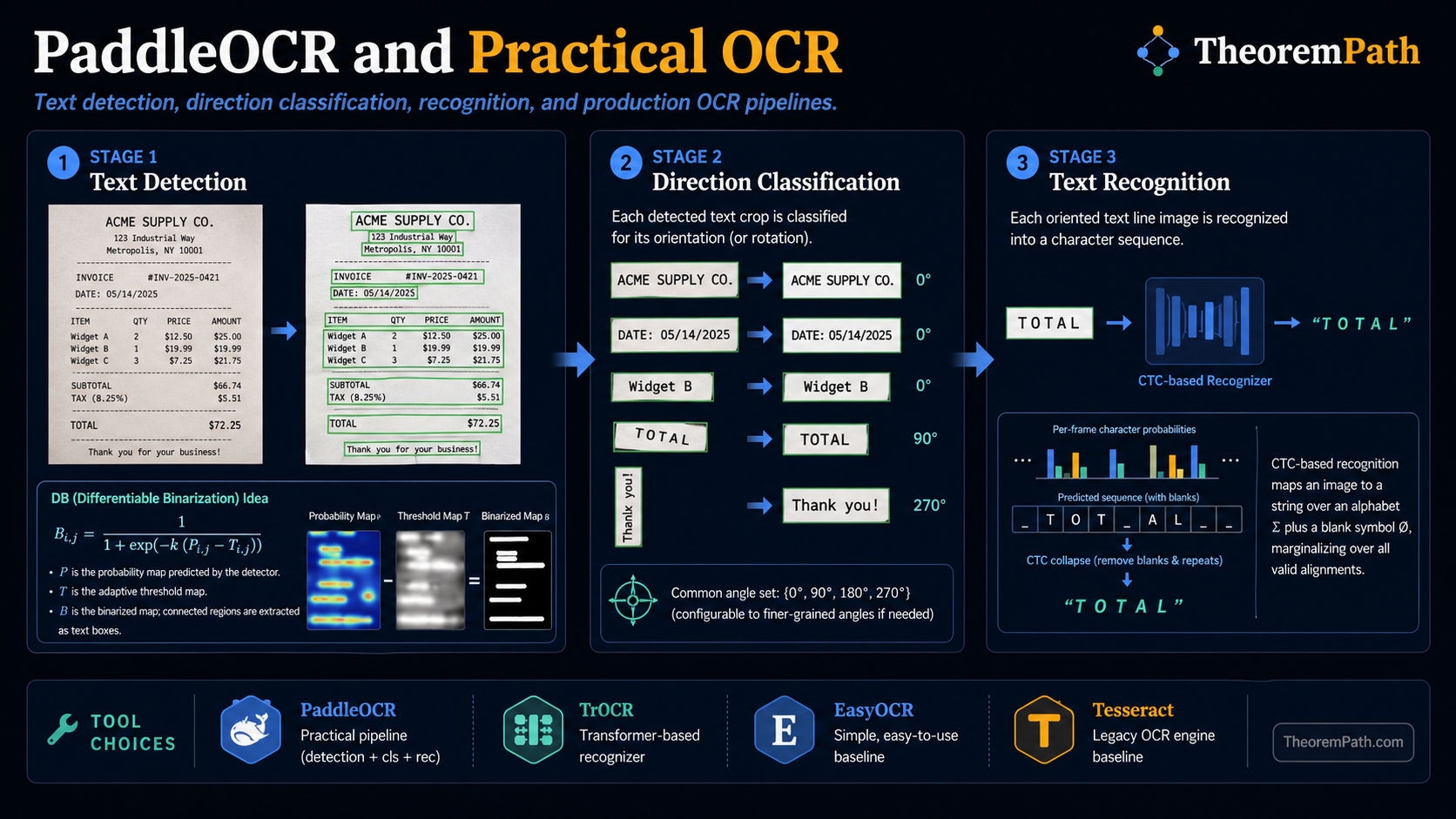
Modern OCR is not a single model. It is a pipeline of specialized components: detect text regions, classify text direction, recognize characters. Each component has its own architecture and failure modes. Knowing these components lets you diagnose and fix extraction failures.
Mental Model
OCR operates in three stages:
- Text detection: find rectangular regions containing text in the image
- Direction classification: determine if each text region is rotated or mirrored
- Text recognition: convert each cropped text region into a character string
Each stage is a separate model. Detection is an object detection problem. Classification is a simple image classifier. Recognition is a sequence prediction problem (image to string).
Formal Setup and Notation
Text Detection
Given a document image , text detection produces a set of bounding regions where each is a polygon (typically a quadrilateral) enclosing a text line or word. The Differentiable Binarization (DB) method used in PaddleOCR predicts a probability map and a threshold map :
where controls binarization sharpness (typically ). Text regions are extracted as connected components from the binarized map .
CTC-Based Text Recognition
Given a cropped text image resized to fixed height and variable width , a recognition model produces a probability distribution over characters at each horizontal position. Let be the character alphabet augmented with a blank token . The model outputs where for stride .
The CTC decoding collapses repeated characters and removes blanks:
For example, the raw output "hh-ee-ll-ll-oo" (where - is blank) decodes to "hello".
Core Definitions
PaddleOCR is an open-source multilingual OCR toolkit from Baidu, supporting 80+ languages. Its default pipeline uses:
- DB (Differentiable Binarization) for text detection: a segmentation network that predicts text/non-text probability per pixel, then extracts bounding polygons from connected components.
- SVTR (Scene Text Recognition with a Vision Transformer) or CRNN for text recognition: encodes the cropped text image and decodes character sequences.
- A lightweight classifier for text direction (0 or 180 degrees).
TrOCR (Microsoft) uses a Vision Transformer encoder and a text transformer decoder. The encoder is initialized from a pretrained ViT (DeiT or BEiT). The decoder is initialized from a pretrained language model (RoBERTa or GPT-2). This exploits large-scale vision and language pretraining for OCR.
EasyOCR is a Python library supporting 80+ languages, using CRAFT for detection and a CRNN for recognition. Simpler to deploy than PaddleOCR, but generally less accurate on complex layouts.
Tesseract (Google, originally HP Labs) is the classical open-source OCR engine. Version 4+ uses an LSTM-based recognizer. It works well on clean, single-column, printed text. It struggles with complex layouts, mixed languages, and unusual fonts.
Main Theorems
CTC Loss for Sequence Recognition
Statement
The CTC (Connectionist Temporal Classification) loss marginalizes over all valid alignments between the feature sequence and the target string. For target string , define the set of valid CTC paths:
The CTC loss is:
This sum is computed efficiently in using a forward-backward algorithm analogous to HMM inference.
Intuition
CTC solves the alignment problem: we know the image says "hello" but we do not know which pixel columns correspond to which characters. CTC considers all possible alignments (including inserting blanks between characters) and maximizes their total probability. The model learns to produce spiky probability peaks at character positions and blanks elsewhere.
Proof Sketch
The forward-backward algorithm defines forward variable as the total probability of all paths producing prefix at time . The recurrence handles three cases: staying on the same character, advancing to the next character, or emitting a blank. The total CTC probability is (accounting for interleaved blanks). This runs in time, making it tractable for gradient-based training.
Why It Matters
CTC is the standard training objective for CRNN-based text recognizers in PaddleOCR, EasyOCR, and Tesseract 4+. Without CTC, you would need character-level bounding box annotations for training, which are extremely expensive to obtain. CTC only requires the image and the target string.
Failure Mode
CTC assumes a monotonic alignment: characters appear left-to-right in the image. This fails for curved text, circular text, or bidirectional scripts where the visual order differs from the reading order. CTC also struggles when is much larger than (very wide images with short text), as the model must learn to emit many consecutive blanks. Attention-based decoders (as in TrOCR) handle these cases better.
PaddleOCR Pipeline in Detail
PaddleOCR 3.0 extends beyond basic OCR with additional modules:
- Document parsing: segmenting a page into text blocks, tables, figures, headers, and footers (similar to layout analysis in LayoutLM systems)
- Table recognition: detecting table structure and extracting cell content
- Key information extraction: extracting named fields from structured documents like receipts and invoices
- Seal text recognition: reading text arranged in circular seals (common in Chinese business documents)
The pipeline is modular: you can replace individual components without retraining the entire system. For example, swapping DB for a more accurate detector while keeping the same recognizer.
TrOCR: Transformer-Native OCR
TrOCR replaces both the CNN feature extractor and the CTC/attention decoder with transformers. The encoder (ViT) splits the text line image into patches and processes them with self-attention. The decoder generates characters autoregressively with cross-attention to encoder outputs.
Advantages over CRNN+CTC: TrOCR handles variable-length outputs naturally (no CTC alignment needed), benefits from pretrained vision and language models, and achieves leading accuracy on standard benchmarks as of 2024. Reported numbers in Li et al. (2023): TrOCR-Large hits 2.89% CER on IAM handwriting, and TrOCR-Base reaches 95.84 F1 on SROIE printed receipts. Always check the specific variant (Small / Base / Large) before quoting a number; the gap between Small and Large is 3-5 percentage points on most benchmarks.
Disadvantage: TrOCR is slower than CRNN at inference due to autoregressive decoding. For high-throughput production pipelines processing millions of documents, CRNN+CTC is often preferred.
VLM-Based OCR
Large vision-language models (GPT-4V, Claude 3 Opus and Sonnet with vision, Gemini 1.5, Qwen-VL, InternVL) can read text directly from a document image with a prompt like "transcribe all text in reading order." This bypasses the detect→classify→recognize pipeline entirely.
Trade-offs vs specialized OCR:
- Accuracy on clean printed text: roughly matches PaddleOCR / TrOCR on invoices, receipts, and screenshots in English, Chinese, Japanese. On complex layouts (multi-column scientific papers, forms, tables), frontier VLMs often beat pipeline OCR because they implicitly do layout analysis.
- Accuracy on handwriting and low-resource scripts: worse than TrOCR / PaddleOCR for handwriting benchmarks as of early 2026; frontier VLMs are trained mostly on printed text.
- Latency and cost: 100-1000x slower per page than PaddleOCR on CPU, and 1-10 USD per 1k pages via API vs near-zero amortized cost for self-hosted CRNN. Token cost scales with image resolution and number of pages.
- No bounding boxes: VLMs return a text string but not the pixel coordinates of each word. For downstream tasks that need coordinates (redaction, table cell linking, form-field targeting), you still need PaddleOCR or a hybrid pipeline.
- Hallucination risk: VLMs occasionally invent plausible text where the image is ambiguous or low-resolution, while CRNN/TrOCR fail more loudly (garbled characters, empty output). This matters for regulated domains (medical, legal, finance) where silent errors are worse than loud ones.
A common production pattern as of 2026: use PaddleOCR for high-volume structured documents (invoices, IDs, forms) where coordinates and cost matter, and reserve VLM-based OCR for complex one-off tasks (academic PDFs, mixed-layout reports) where layout understanding matters more than throughput.
Commercial OCR APIs
Closed-source production services (AWS Textract, Google Document AI, Azure Document Intelligence, Mistral OCR) wrap text detection, recognition, and layout analysis into a single managed endpoint. They typically combine a strong detector, a CRNN-style or transformer recognizer, and layout heuristics. Accuracy is competitive with PaddleOCR on common document types, with the benefit of SLAs, PII redaction features, and form-field extraction. Cost is typically 1-5 USD per 1k pages. The right pick when you cannot self-host GPUs or need vendor accountability for compliance.
When to Use Which
| Scenario | Recommended Tool | Reason |
|---|---|---|
| Production pipeline, multilingual | PaddleOCR | Best accuracy-speed trade-off, 80+ languages |
| Research, pushing accuracy | TrOCR | Strong on IAM / SROIE, pretrained initialization |
| Quick prototype, Python | EasyOCR | Simple API, pip install, reasonable accuracy |
| Clean printed English text | Tesseract | Lightweight, no GPU needed, good enough |
| Handwritten text | TrOCR or PaddleOCR v4 | CRNN-based models struggle with handwriting |
| Complex layouts, one-off PDFs | Frontier VLM (GPT-4V / Claude / Gemini) | Implicit layout analysis, no pipeline tuning |
| Compliance-critical, managed SLA | AWS Textract / Google Document AI / Azure DI | Vendor accountability, PII redaction built-in |
Common Confusions
OCR accuracy metrics can be misleading
Character Error Rate (CER) and Word Error Rate (WER) are computed on cropped, pre-detected text regions. They do not account for detection errors (missed text, false detections). A system with 99% CER but 80% text detection recall misses 20% of the text entirely. Always evaluate the full pipeline, not just the recognizer.
Language support does not mean equal accuracy
PaddleOCR supports 80+ languages, but accuracy varies dramatically. Chinese, English, and Japanese have millions of training samples. Low-resource languages (Tibetan, Khmer) have far fewer and correspondingly lower accuracy. Check benchmark numbers for your specific language before committing to a toolkit.
GPU is not always necessary for OCR
PaddleOCR and Tesseract run on CPU with acceptable latency for single-document processing (under 1 second per page). GPU acceleration matters for batch processing thousands of pages. Do not over-engineer the infrastructure for a prototype that processes 10 documents per day.
Exercises
Problem
A CRNN text recognizer processes a cropped text image of width 320 pixels with a CNN that downsamples width by a factor of 4, producing a feature sequence of length . The target text is "Invoice" (7 characters). Explain why CTC can handle this mismatch between and .
Problem
TrOCR uses autoregressive decoding while CRNN uses CTC (parallel decoding). Analyze the inference time complexity of each approach for a text line of characters, given encoder output of length .
References
Canonical (detection and recognition backbones):
- Shi et al., An End-to-End Trainable Neural Network for Image-Based Sequence Recognition (CRNN) (2015), arXiv:1507.05717, Sections 2-3. The original CRNN that set the CNN + BiLSTM + CTC template.
- Graves et al., Connectionist Temporal Classification (2006), ICML, Sections 3-4. The CTC forward-backward derivation.
- Baek et al., Character Region Awareness for Text Detection (CRAFT) (2019), arXiv:1904.01941. Character-level detection used by EasyOCR and many research pipelines.
- Wang et al., Shape Robust Text Detection with Progressive Scale Expansion Network (PSENet) (2019), CVPR, arXiv:1903.12473. Segmentation-based detector that handles arbitrarily shaped text and predates DB in many production stacks.
- Liao et al., Real-Time Scene Text Detection with Differentiable Binarization (DB) (2020), AAAI, arXiv:1911.08947. The detector used in PaddleOCR.
- Du et al., SVTR: Scene Text Recognition with a Single Visual Model (2022), IJCAI, arXiv:2205.00159. The vision-transformer recognizer used in PaddleOCR v4.
- Bautista & Atienza, Scene Text Recognition with Permuted Autoregressive Sequence Models (PARSeq) (2022), ECCV, arXiv:2207.06966. Replaces strictly left-to-right CTC/AR decoding with permuted autoregression; strong on irregular scene text.
- Wang et al., Multi-Granularity Prediction for Scene Text Recognition (MGP-STR) (2022), ECCV, arXiv:2209.03592. Joint character/subword/word prediction for STR.
- Li et al., TrOCR: Transformer-based Optical Character Recognition (2023), AAAI, arXiv:2109.10282. Benchmark numbers cited above are from Table 2 (printed) and Table 3 (handwritten).
Frontier (2024-2025):
- Wei et al., General OCR Theory: Towards OCR-2.0 via a Unified End-to-End Model (GOT-OCR 2.0) (2024), arXiv:2409.01704. End-to-end OCR-as-decoding model that matches or beats pipeline OCR on documents while emitting Markdown / LaTeX directly.
- AllenAI, olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models (2025), arXiv:2502.18443. Open-weight VLM-based OCR pipeline tuned for academic-PDF extraction at scale.
- Wang et al., MinerU: An Open-Source Solution for Precise Document Content Extraction (2024), arXiv:2409.18839. Layout-first pipeline that combines a strong detector, formula and table recognition, and reading-order recovery.
Production and tooling:
- PaddleOCR documentation and benchmarks, github.com/PaddlePaddle/PaddleOCR
- Tesseract 4 LSTM engine notes, github.com/tesseract-ocr/tesseract/wiki
- AWS Textract, Google Document AI, Azure Document Intelligence, and Mistral OCR product documentation for managed OCR + layout APIs.
VLM-based OCR (frontier, read critically):
- OpenAI GPT-4V system card (2023) and Anthropic Claude 3 model card (2024) for vision capabilities on document text.
- Bai et al., Qwen-VL (2023), arXiv:2308.12966. Open-weight VLM with strong OCR on Chinese and English documents.
- Chen et al., InternVL (2023), arXiv:2312.14238. Open-weight VLM often competitive on document benchmarks.
Last reviewed: April 26, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
1- Document Intelligencelayer 5 · tier 2
Derived topics
2- Donut and OCR-Free Document Understandinglayer 5 · tier 3
- Table Extraction and Structure Recognitionlayer 5 · tier 3
Graph-backed continuations