LLM Construction
Donut and OCR-Free Document Understanding
End-to-end document understanding without OCR: Donut reads document images directly and generates structured output, bypassing the error-prone OCR pipeline. Nougat extends this to academic paper parsing.
Why This Matters
Traditional document intelligence pipelines rely on OCR as a first step: extract text, then reason about it. This creates a hard dependency on OCR quality. When OCR fails (handwritten text, degraded scans, unusual fonts, low-resolution images), every downstream component fails too. Errors compound through the pipeline.
Hide overviewShow overview
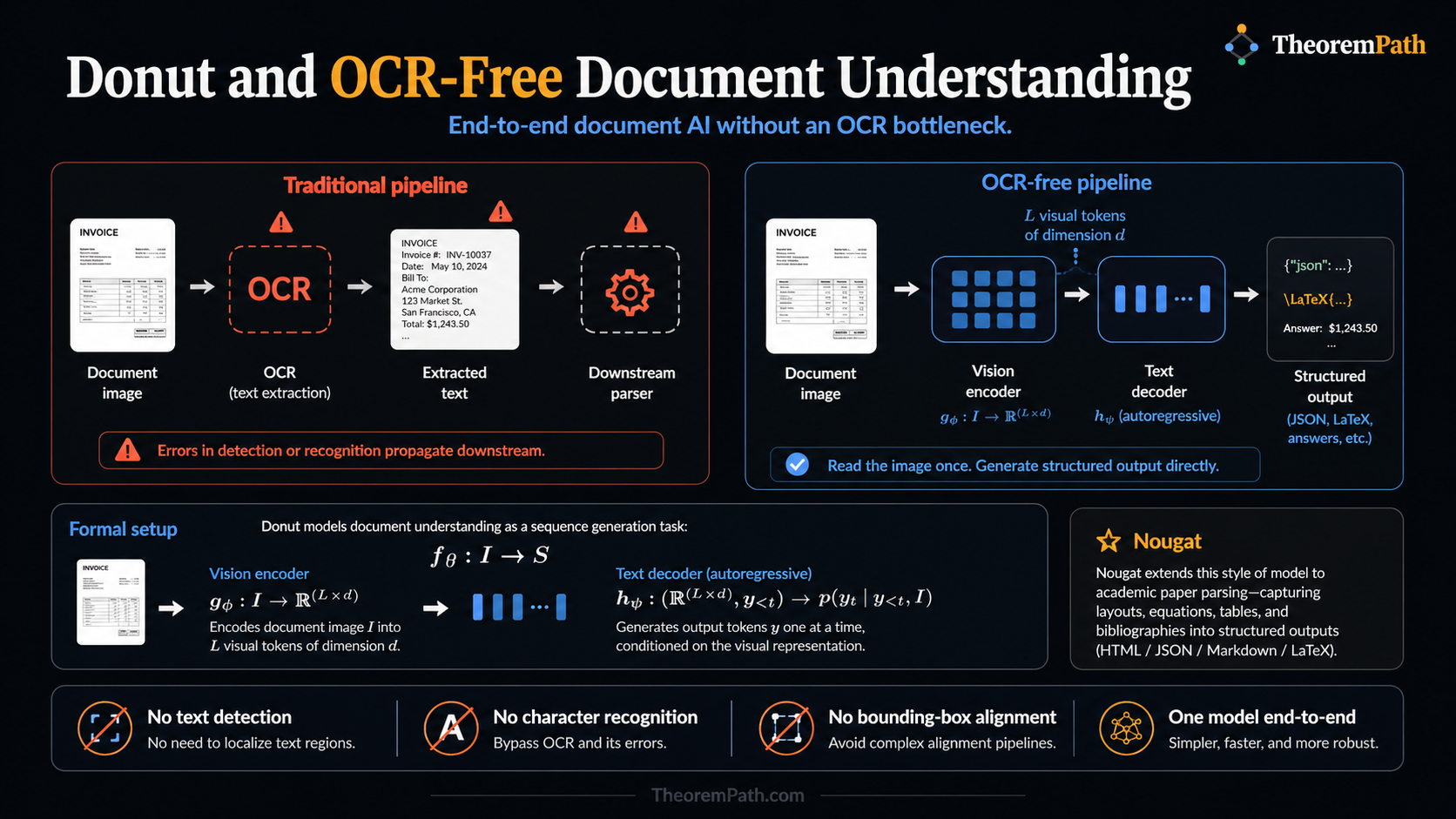
OCR-free models sidestep this entirely. They take a document image as input and produce structured output directly. No text detection, no character recognition, no bounding box alignment. One model, end to end.
Mental Model
Think of the difference between reading a document with your eyes versus having someone transcribe it for you first. If the transcriber makes errors, you reason over corrupted text. OCR-free models "read with their eyes": a vision encoder processes the raw pixels, and a text decoder generates the desired output (JSON fields, LaTeX, answers to questions).
Formal Setup and Notation
OCR-Free Document Model
An OCR-free document model is a function where is the space of document images and is the space of structured text sequences. The model consists of:
- A vision encoder producing visual tokens of dimension
- A text decoder that autoregressively generates output tokens conditioned on visual features
No OCR module appears in this pipeline. The encoder must learn to "read" directly from pixels.
Prompted Output Generation
For tasks like key information extraction, the model is prompted with a task token. Given image and task prompt (e.g., "[extract_invoice]"), the model generates:
The output is a structured string (JSON, XML, or LaTeX) that can be parsed into typed fields.
Core Definitions
The Donut (Document Understanding Transformer) architecture uses a Swin Transformer as the vision encoder and a BART-style decoder for text generation. The encoder processes the document image at high resolution (typically pixels) and outputs a sequence of visual feature vectors. The decoder generates output tokens conditioned on these features.
Nougat (Neural Optical Understanding for Academic Documents) applies the same OCR-free principle to academic papers. Given a PDF page rendered as an image, Nougat outputs the corresponding LaTeX/Markdown source. This is useful for converting legacy papers to machine-readable formats.
The teacher forcing training procedure is standard: given ground-truth output sequence , minimize the cross-entropy loss at each position conditioned on the true prefix.
Main Theorems
OCR-Free Training Objective
Statement
The Donut training objective minimizes:
where are image-text pairs. The output sequence encodes the structured extraction target as a serialized string (e.g., JSON with special tokens for field names).
For Donut, the SwinTransformer encoder processes the image at resolution with patch size , producing visual tokens. These tokens serve as the cross-attention keys and values for the decoder.
Intuition
This is the same sequence-to-sequence objective used in machine translation, but the "source language" is an image and the "target language" is structured text. The model must learn OCR, layout understanding, and information extraction simultaneously from the single training signal of next-token prediction.
Proof Sketch
No formal proof. This is a training objective, not a theorem about guarantees. The empirical result from Kim et al. (2022) is that Donut achieves competitive performance with OCR-dependent models on standard benchmarks (CORD, RVL-CDIP) despite receiving no explicit text supervision.
Why It Matters
Collapsing the entire document understanding pipeline into a single differentiable model eliminates cascading errors. OCR mistakes cannot propagate because there is no OCR. The model also naturally handles visual cues that OCR discards: font weight, color, spatial grouping.
Failure Mode
OCR-free models require large training sets of image-text pairs. On clean, well-structured documents where OCR achieves over 99% character accuracy, OCR-based pipelines still outperform Donut. The OCR-free approach wins on noisy inputs (handwriting, degraded scans) where OCR fails. Resolution matters: if the input image is too small, the encoder cannot resolve individual characters.
Donut Architecture Details
The Donut encoder uses a Swin Transformer pretrained on document images (IIT-CDIP dataset, 11M document images). Pretraining uses a pseudo-OCR task: given an image, predict the text it contains. This teaches the encoder to extract textual information from pixels without an explicit OCR module.
The decoder uses learned prompt tokens to specify the extraction task. Different prompts produce different output formats from the same encoder. For document classification, the output is a single class token. For KIE, the output is a JSON-like string with field names and values.
Nougat for Academic Papers
Nougat processes each page of a PDF independently. The training data consists of PDF page images paired with LaTeX source from arXiv papers. The model learns to reverse-render: given the visual output of LaTeX compilation, recover the source code.
Key challenge: mathematical notation. LaTeX has many ways to express the same formula, so the training must normalize the target representation. Nougat handles equations, tables, figures (as placeholders), and multi-column layouts.
Observed limitation: Nougat sometimes hallucinates repetitive text on pages with unusual layouts. A repetition detection heuristic is used at inference time to catch and truncate these failures.
Successors: Generative Document Models
The OCR-free principle in Donut/Nougat has been extended by a wave of unified generative document models that emit Markdown, HTML, or JSON directly from page images:
- UDOP (Tang et al., 2023) unifies vision, text, and layout under a prompt-conditioned encoder-decoder.
- Pix2Struct (Lee et al., 2023) pretrains by predicting screenshot HTML and transfers to charts, infographics, UIs, and documents.
- Kosmos-2.5 (Lv et al., 2023) targets text-rich images with both Markdown and grounded text outputs.
- GOT-OCR 2.0 (Wei et al., 2024) recasts OCR as general "image to arbitrary-format text" generation, supporting plain text, Markdown, LaTeX, and table HTML in one decoder.
- olmOCR (Allen AI, 2024) ships an open-weight OCR-free model trained for high-throughput pretraining-data extraction.
These systems share Donut's core bet (skip the OCR boundary, train end to end) but expand the output space and model scale substantially. See the document intelligence page for deployment context and the open-source conversion stacks (Marker, Docling, MinerU) that combine these models with layout detection and post-processing.
When OCR-Free Wins and Loses
On the CORD receipt extraction benchmark, Donut achieves 84.1% F1 without any OCR, compared to 86.3% for LayoutLMv2 with OCR. On handwritten form understanding, OCR-free models close the gap further because OCR accuracy on handwriting is much lower.
The trade-off: OCR-free models are architecturally simpler (one model instead of a pipeline) but currently less accurate on clean, printed documents. They are better suited to scenarios where OCR quality is unreliable or where deployment simplicity matters more than peak accuracy.
Common Confusions
OCR-free does not mean the model ignores text
Donut learns to read text from pixels during pretraining. It performs implicit character recognition inside the vision encoder. The difference is that this recognition is end-to-end differentiable and jointly optimized with downstream tasks, rather than being a separate, fixed preprocessing step.
High resolution is not optional
OCR-free models need high input resolution to distinguish individual characters. A image (standard for ImageNet classification) is far too small. Donut uses . Reducing resolution degrades performance sharply because the model literally cannot see the text.
Exercises
Problem
A Donut encoder uses a Swin Transformer with patch size on a input image. After 3 patch-merging operations (Swin's 4 stages have 3 downsamplings between them, each by factor 2), how many visual tokens does the encoder produce?
Problem
Explain why OCR-free models are more robust to document degradation (stains, folds, faded ink) than OCR-based pipelines, even when both use the same vision encoder capacity.
References
Canonical:
- Kim et al., OCR-free Document Understanding Transformer (Donut) (2022), ECCV, Sections 3-4
- Blecher et al., Nougat: Neural Optical Understanding for Academic Documents (2023), arXiv:2308.13418
Generative successors:
- Tang et al., Unifying Vision, Text, and Layout for Universal Document Processing (UDOP) (2023), CVPR, arXiv:2212.02623
- Lee et al., Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding (2023), ICML, arXiv:2210.03347
- Lv et al., Kosmos-2.5: A Multimodal Literate Model (2023), arXiv:2309.11419
- Wei et al., General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model (GOT-OCR 2.0) (2024), arXiv:2409.01704
- Poznanski et al., olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models (Allen AI, 2024), arXiv:2502.18443
Surveys and comparison:
- Davis et al., End-to-End Document Recognition and Understanding: A Survey (2023), IJDAR
- Xu et al., LayoutLMv3 (2022), for comparison with OCR-dependent approaches
Last reviewed: April 26, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
3- Transformer Architecturelayer 4 · tier 2
- Document Intelligencelayer 5 · tier 2
- PaddleOCR and Practical OCRlayer 5 · tier 2
Derived topics
0No published topic currently declares this as a prerequisite.