Optimization Function Classes
Riemannian Optimization and Manifold Constraints
Optimization on curved spaces: the Stiefel manifold for orthogonal matrices, symmetric positive definite matrices, Riemannian gradient descent, retractions, and why flat-space intuitions break on manifolds. The geometric backbone of Shampoo, Muon, and constrained neural network training.
Prerequisites
Why This Matters
Standard gradient descent assumes parameters live in flat Euclidean space . But many ML problems have constraints that define curved spaces: weight matrices that must stay orthogonal, covariance matrices that must stay positive definite, probability distributions that must stay on the simplex, or embeddings that must stay on a sphere.
Hide overviewShow overview
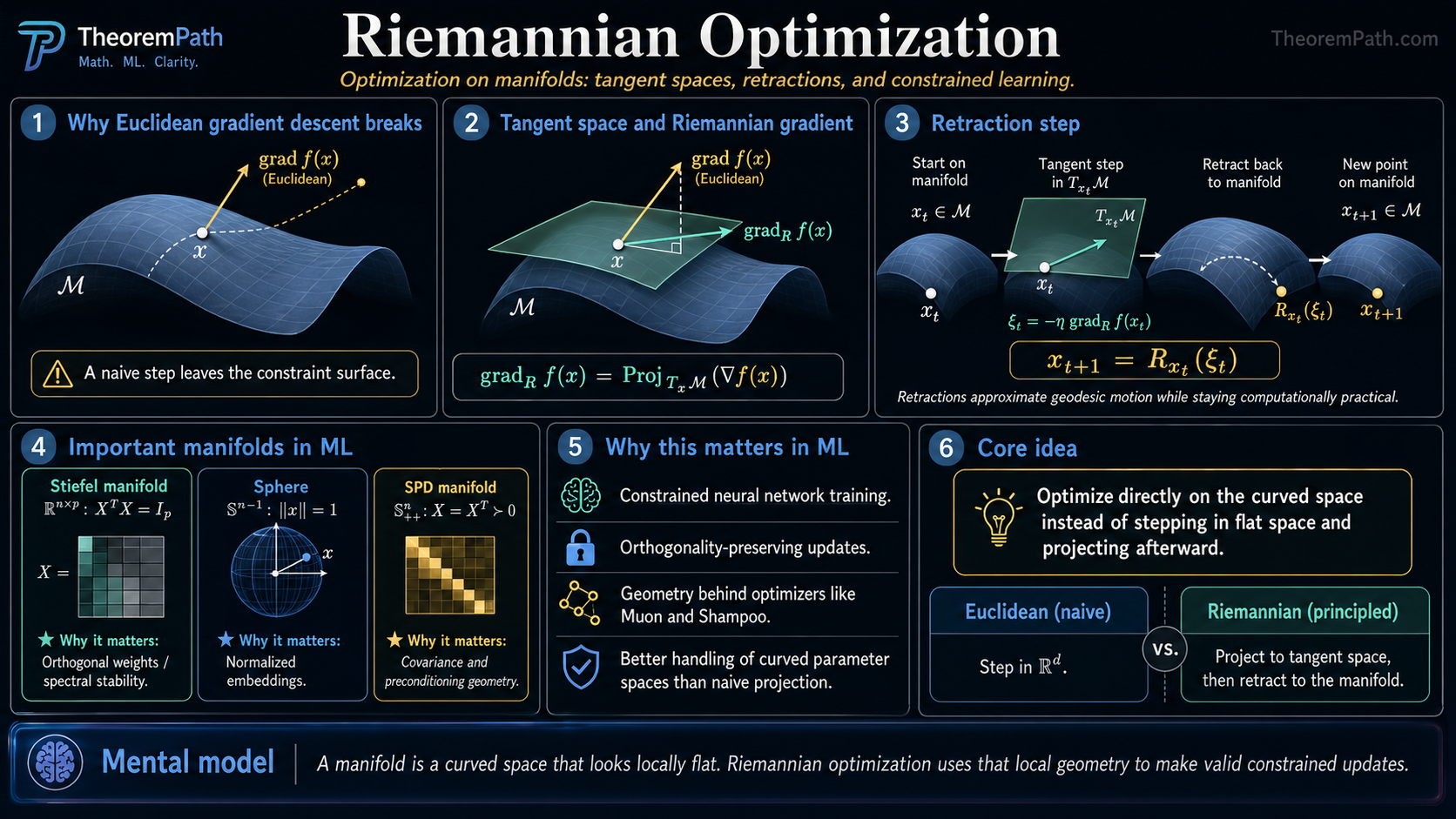
If you just project back to the constraint set after each gradient step, you waste computation and can get poor convergence. Riemannian optimization does better: it works directly on the curved surface (manifold), computing gradients that are tangent to the surface and taking steps that stay on it.
This is not esoteric geometry. The Muon optimizer uses Newton-Schulz iteration to approximate projection onto the Stiefel manifold. Shampoo preconditions gradients using the space of symmetric positive definite matrices. Understanding the manifold geometry explains why these optimizers work and where they fail.
Core Concepts
Smooth Manifold
A smooth manifold is a space that locally looks like but may be globally curved. Each point has a tangent space , a vector space of directions you can move from while staying on (infinitesimally).
For ML, the key manifolds are:
- The Stiefel manifold : matrices with orthonormal columns
- The SPD manifold : symmetric positive definite matrices
- The sphere : unit vectors
- The Grassmannian : -dimensional subspaces of
Riemannian Metric
A Riemannian metric assigns an inner product to each tangent space, varying smoothly with . This defines distances, angles, and curvature on the manifold.
For the Stiefel manifold embedded in , the simplest metric is the inherited Euclidean one: for tangent vectors .
Riemannian Gradient
The Riemannian gradient of at is the tangent vector such that:
For a submanifold of , this is the projection of the Euclidean gradient onto the tangent space:
The Riemannian gradient points in the steepest descent direction on the manifold, ignoring directions that would leave the constraint surface.
The Stiefel Manifold
The Stiefel manifold is the most important manifold in ML optimization because orthogonality constraints appear in neural network weight matrices, embedding layers, and preconditioner updates.
Tangent Space and Retraction on the Stiefel Manifold
Statement
The tangent space of the Stiefel manifold at is:
The Riemannian gradient of at is obtained by projecting the Euclidean gradient :
where . A retraction (first-order approximation to the exponential map) is the QR-based retraction:
where extracts the factor from QR decomposition.
Intuition
The tangent space condition says that tangent directions must be "skew" relative to . Moving in direction from should keep close to to first order. The projection removes the component of the Euclidean gradient that would move off the manifold. The retraction maps back to the manifold after taking a step.
Why It Matters
This is exactly what Muon's Newton-Schulz iteration approximates. Instead of the expensive QR decomposition, Newton-Schulz uses polynomial iterations to approximate the orthogonal polar factor, which is another valid retraction. The choice of retraction affects computational cost but not the direction of descent (to first order).
Shampoo also uses the Stiefel manifold implicitly: its preconditioner updates maintain structure on the space of positive definite matrices, and the Kronecker factorization exploits the product structure of weight matrices.
Failure Mode
QR retraction costs , which is expensive for large matrices. Cayley retraction and polar retraction are alternatives with different cost-accuracy tradeoffs. For very large (e.g., transformer weight matrices with ), even the retraction cost can dominate training time, which is why approximations like Newton-Schulz are used in practice.
Exponential Map on the Stiefel Manifold
The true exponential map sends a tangent vector to the endpoint of the geodesic starting at with velocity . Edelman, Arias, and Smith (1998) gave the closed form:
where is the matrix exponential. This requires exponentiating a matrix and an additional matrix, giving work per step (on top of forming ). In practice, cheaper first-order retractions such as QR or polar are used because the geodesic accuracy does not change first-order convergence rates, and the matrix exponential cost dominates for large .
Parallel Transport vs Vector Transport
To combine tangent vectors from different points (as Riemannian BFGS or conjugate gradient must when updating search directions), one needs a way to move a vector to . Parallel transport along a geodesic preserves the Riemannian inner product and is the geometrically canonical choice, but computing it on the Stiefel or SPD manifolds requires solving an ODE or integrating the Levi-Civita connection, which is expensive. Vector transport is any smooth map that approximates parallel transport to first order. A common cheap choice on embedded manifolds is to project the ambient vector onto . Manifold BFGS, L-BFGS, and conjugate gradient all use vector transports rather than true parallel transport because the extra approximation error does not harm superlinear or linear convergence under standard assumptions.
Riemannian Gradient Descent
Riemannian Gradient Descent
Statement
Riemannian gradient descent updates:
where is a retraction. Under geodesic -smoothness (the Riemannian analog of -smoothness), with step size :
where is the geodesic distance. This matches the Euclidean rate.
Intuition
Riemannian gradient descent is the direct analog of Euclidean gradient descent: compute the steepest descent direction (now on the manifold), take a step (now using the retraction instead of addition), and repeat. The convergence theory parallels the Euclidean theory, with geodesic convexity and smoothness replacing their Euclidean counterparts.
Why It Matters
This guarantees that constrained optimization on manifolds is not harder in rate than unconstrained optimization. The same rate holds, and with geodesic strong convexity you get the same linear rate. The manifold structure is exploited, not fought against.
Failure Mode
Geodesic convexity is a stronger requirement than Euclidean convexity restricted to the manifold. Some functions that are convex in are not geodesically convex on curved manifolds, and vice versa. The curvature of the manifold introduces additional terms in the convergence analysis. On manifolds with high curvature (small injectivity radius), the step size must be correspondingly small.
Why Low-Rank Does Not Mean Low Complexity
Low rank does not mean simple or easy to optimize
Low-rank approximation via SVD truncation is a Euclidean operation: find the closest rank- matrix in Frobenius norm. But the set of rank- matrices is not a convex set and not even a smooth manifold (it has singularities where the rank drops further). The smooth part (matrices of exactly rank ) forms a manifold, but it has curvature that depends on the singular value gaps.
Optimizing over low-rank matrices is a non-convex problem. The landscape has saddle points corresponding to singular value crossings. Riemannian optimization on the fixed-rank manifold avoids the singularities and can converge provably, but it requires careful treatment of the tangent space (which involves both the column space and row space of the matrix).
The Stiefel manifold is not flat
The Stiefel manifold is a curved space embedded in . Straight-line steps in the ambient space leave the manifold. This is not just a technical nuisance: the curvature means that parallel transport (moving vectors from one tangent space to another) is path-dependent, and the shortest path between two orthogonal matrices (the geodesic) is not a straight line but a matrix exponential curve.
For the special case (orthogonal group ), the geodesics are where is skew-symmetric. The curvature of is positive and equals in appropriate normalization.
SPD Matrices and the Information Geometry Connection
The manifold of symmetric positive definite (SPD) matrices appears in ML through covariance estimation, Fisher information matrices, kernel matrices, and preconditioner design.
The natural metric on is the affine-invariant metric:
Under this metric, the geodesic distance between two SPD matrices is:
This connects directly to information geometry: the Fisher information metric on statistical models induces the affine-invariant metric on the space of Gaussian covariance matrices. Shampoo's preconditioner updates operate on this space.
Hyperbolic Manifolds for Hierarchical Embeddings
Hyperbolic space has constant negative curvature and grows exponentially with radius, which makes it a natural host for tree-like and taxonomic data. The Poincaré ball model is with the conformal metric , giving constant sectional curvature . Distances between points near the boundary become very large, so the ball has room to embed exponentially many nodes while preserving tree distances with low distortion. Nickel and Kiela (2017) showed that Poincaré embeddings recover hierarchies (WordNet nouns, taxonomies) with lower distortion and fewer dimensions than Euclidean embeddings. Riemannian SGD on uses the Möbius addition and the closed-form exponential map , where is the conformal factor.
Exercises
Problem
Verify that the tangent space condition is necessary for to be tangent to at . Start from the constraint and differentiate.
Problem
The polar retraction on the Stiefel manifold is . Show that this maps back to , i.e., verify . Why is this preferred over QR retraction in some settings?
References
Canonical:
- Absil, Mahony, Sepulchre, Optimization Algorithms on Matrix Manifolds (2008). The definitive reference.
- Edelman, Arias, Smith, "The Geometry of Algorithms with Orthogonality Constraints" (SIMAX, 1998). Foundational paper on Stiefel/Grassmann optimization.
Current:
- Boumal, An Introduction to Optimization on Smooth Manifolds (2023). Modern textbook, freely available.
- Hu et al., "Brief Introduction to Manifold Optimization" (JMLR, 2020)
- Becigneul & Ganea, "Riemannian Adaptive Optimization Methods" (ICLR 2019). Riemannian Adam.
- Lezcano-Casado, "Trivializations for Gradient-Based Optimization on Manifolds" (NeurIPS 2019, arXiv:1909.09501). Reparameterization approach to manifold optimization.
Frontier:
- Jordan, Jin, Boza, Bernstein, You, Cesista, Newhouse, "Muon: An Optimizer for Hidden Layers in Neural Networks" (2024). Newton-Schulz-based approximate Stiefel retraction for neural network training.
- Bernstein & Newhouse, "Old Optimizer, New Norm: An Anthology" (2024, arXiv:2409.20325). Unified view of optimizers through induced operator norms.
- Nickel & Kiela, "Poincaré Embeddings for Learning Hierarchical Representations" (NeurIPS 2017, arXiv:1705.08039). Hyperbolic embeddings for tree-structured data.
Software:
- Townsend, Koep, Weichwald, "Pymanopt: A Python Toolbox for Optimization on Manifolds using Automatic Differentiation" (JMLR 2016, arXiv:1603.03236).
- Boumal, Mishra, Absil, Sepulchre, "Manopt, a Matlab Toolbox for Optimization on Manifolds" (JMLR 15:1455-1459, 2014). The original MATLAB library.
- Miolane et al., "Geomstats: A Python Package for Riemannian Geometry in Machine Learning" (JMLR 21:1-9, 2020). Python library for geometric statistics and learning.
Next Topics
- Optimizer theory: SGD, Adam, Muon: how Muon uses Newton-Schulz to approximate Stiefel retraction
- Second-order optimization: natural gradient and preconditioned methods that operate on manifold structure
Last reviewed: April 18, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
8- Eigenvalues and Eigenvectorslayer 0A · tier 1
- The Hessian Matrixlayer 0A · tier 1
- Convex Optimization Basicslayer 1 · tier 1
- Non-Euclidean and Hyperbolic Geometrylayer 1 · tier 2
- Hyperbolic Embeddings for Graphslayer 2 · tier 2
Derived topics
2- Optimizer Theory: SGD, Adam, and Muonlayer 3 · tier 1
- Second-Order Optimization Methodslayer 3 · tier 2
Graph-backed continuations