Applied Math
Number Theory and Machine Learning
The emerging two-way street between number theory and machine learning: how number-theoretic tools improve ML systems, and how ML is discovering new mathematical structure in classical problems.
Why This Matters
Number theory and machine learning are interacting in ways nobody predicted a decade ago. The interaction runs in both directions: number-theoretic tools (quasi-random sequences, lattice methods, algebraic structure) are improving ML systems, while ML is being used as a discovery tool in pure mathematics, finding patterns in L-functions, elliptic curves, and prime distributions that humans had missed.
Hide overviewShow overview
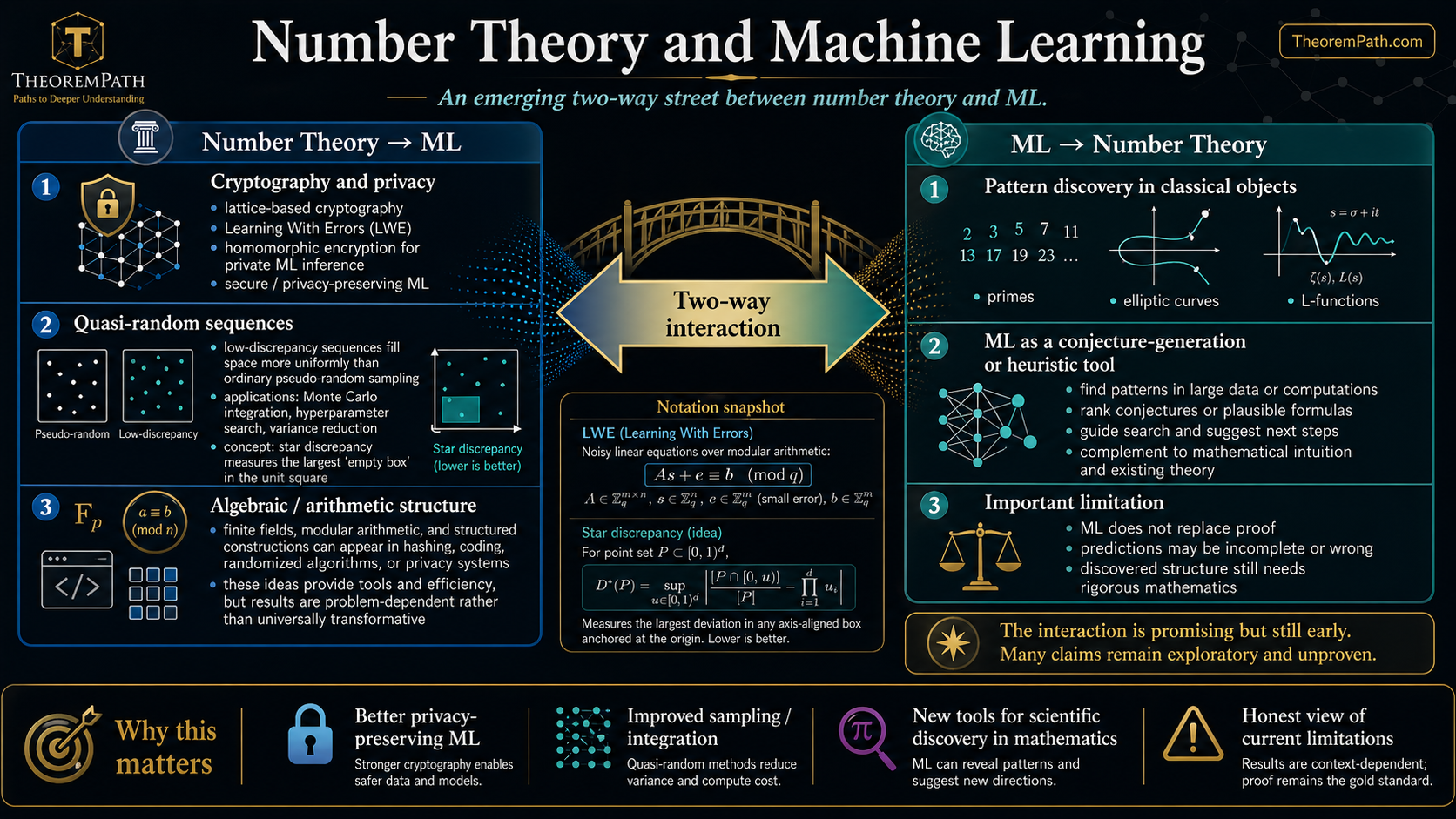
This page maps both directions honestly, including the significant limitations of current approaches.
Number Theory Aiding ML
Cryptography and Privacy
Modern ML increasingly requires privacy. Homomorphic encryption, secure multi-party computation, and differential privacy all rest on number-theoretic hardness assumptions.
Lattice-Based Cryptography
Cryptographic schemes whose security reduces to the hardness of lattice problems such as the Shortest Vector Problem (SVP) or Learning With Errors (LWE). These are the foundation of post-quantum cryptography and enable homomorphic encryption for private ML inference.
The Learning With Errors (LWE) problem, introduced by Regev, is a noisy linear algebra problem over finite fields. Its hardness enables encrypted computation on ML models without revealing the input data.
Quasi-Random Sequences
Standard pseudo-random numbers can cluster, leaving gaps in high-dimensional spaces. Quasi-random (low-discrepancy) sequences fill space more uniformly, improving Monte Carlo integration, hyperparameter search, and initialization. This connects to importance sampling and variance reduction in estimation.
Star Discrepancy
The star discrepancy of a point set measures the worst-case deviation between the empirical distribution and the uniform distribution over anchored boxes with :
where is the class of axis-aligned boxes anchored at the origin. Lower discrepancy means more uniform coverage.
Koksma-Hlawka Inequality
Statement
For a function with finite Hardy-Krause variation on and a point set with star discrepancy :
Intuition
The integration error is controlled by two factors: how rough the function is () and how uniformly the points cover the domain (). Halton, Sobol, and other quasi-random sequences achieve , which beats the rate of random Monte Carlo.
Proof Sketch
Decompose the integration error using a multidimensional integration by parts (the Koksma-Hlawka identity). Each term in the decomposition is bounded by the variation of times the discrepancy of the projection of the point set onto the corresponding coordinate subspace.
Why It Matters
This is why quasi-random hyperparameter search (e.g., Sobol sequences) can outperform grid search and random search, especially in moderate dimensions. The theoretical rate is much better than random sampling's when is not too large.
Failure Mode
In very high dimensions, the factor can dominate, and the advantage of quasi-random sequences over pseudorandom ones diminishes. Above roughly for general functions, the practical benefit is marginal. However, smooth functions with small effective dimension can benefit from quasi-random sequences at much higher .
Input Representation
Positional encodings in transformers use ideas from number theory. The original sinusoidal encoding in the transformer architecture can be viewed through the lens of characters of cyclic groups. More recent work explores representations based on the Chinese Remainder Theorem for encoding positions and numerical values.
ML Aiding Number Theory
The LMFDB and Data-Driven Mathematics
The L-functions and Modular Forms Database (LMFDB) contains billions of mathematical objects: elliptic curves, modular forms, L-functions, number fields. This is a natural target for ML pattern recognition.
ML and the BSD Conjecture
The Birch and Swinnerton-Dyer (BSD) conjecture relates the rank of an elliptic curve to the behavior of its L-function at . ML models trained on LMFDB data have been used to predict the rank of elliptic curves from their conductors and other invariants. While these models do not prove BSD, they help identify which curves deserve closer study and reveal correlations between invariants that suggest new conjectures.
Murmurations: A Genuine Discovery
Murmurations in Elliptic Curves
In 2022-2023, He, Lee, Oliver, and Pozdnyakov used ML to discover murmurations: unexpected oscillatory patterns in the average values of coefficients of elliptic curves when sorted by conductor. The patterns, resembling starling murmurations, were not predicted by any existing theory.
Crucially, after ML flagged the patterns, mathematicians proved the patterns in specific cases (Dirichlet characters mod ) using analytic number theory (trace formulas and explicit formulas for L-functions). The full elliptic curve murmurations conjecture remains open. This is the ideal ML-for-math workflow: ML discovers, humans prove.
Prime Gap Patterns
ML models have been trained to predict the distribution of prime gaps, and reinforcement learning has been applied to optimize sieve methods. However, the results here are more modest: models tend to rediscover known heuristics (the Cramér model, the Hardy-Littlewood conjectures) rather than finding genuinely new structure.
Honest Limitations
ML often finds trivial number-theoretic patterns
When you train a neural network to predict whether a number is prime, it typically learns to check divisibility by small primes (2, 3, 5, 7, ...). This is not deep mathematics; it is pattern matching on the least significant bits. Similarly, models trained to predict prime gaps often learn the residue class structure modulo small primes rather than anything about the deep distribution of primes.
The lesson: always check whether the ML model has learned something genuinely new or merely rediscovered elementary divisibility rules.
ML predictions are not proofs
An ML model predicting the rank of an elliptic curve with 95% accuracy is useful for directing research but proves nothing. In number theory, a conjecture supported by a billion numerical examples but lacking a proof is still a conjecture. The standards of the two fields are incompatibly different, and conflating them helps neither.
Summary
- Number theory provides tools for private ML (lattice crypto, LWE, homomorphic encryption)
- Quasi-random sequences beat random sampling for integration and search in moderate dimensions
- ML has genuinely discovered new mathematical structure (murmurations) that was subsequently proven
- But ML also frequently learns trivial patterns (small-prime divisibility) and mistakes noise for signal
- The ideal workflow: ML discovers, humans verify and prove
Exercises
Problem
Explain why a Sobol sequence with points in gives a better estimate of than uniformly random points, for a smooth function . What is the convergence rate for each?
Problem
A neural network trained to classify numbers as prime or composite achieves 92% accuracy on 6-digit numbers. Before being impressed, what simple baseline should you compare against, and why might the network not have learned anything deep?
Problem
Why is the Learning With Errors (LWE) problem relevant to private ML inference? Sketch how LWE enables computing on encrypted data.
References
Murmurations:
- He, Lee, Oliver, Pozdnyakov, "Murmurations of elliptic curves" (2023). arXiv:2204.10140.
- Sutherland, Zywina, "Murmurations of elliptic curves: analytic proof" (2024)
Quasi-Random Methods:
- Niederreiter, Random Number Generation and Quasi-Monte Carlo Methods (1992)
- Dick, J. & Pillichshammer, F., Digital Nets and Sequences: Discrepancy Theory and Quasi-Monte Carlo Integration, Cambridge University Press (2010)
ML for Number Theory:
- Davies, Juhasz, Sherrill, et al., "Advancing mathematics by guiding human intuition with AI," Nature (2021). arXiv:2111.15161.
- Charton, F., "Linear algebra with transformers," TMLR (2022). arXiv:2112.01898.
LWE and Crypto:
- Regev, "On lattices, learning with errors, random linear codes, and cryptography" (2005)
- Ajtai, M., "Generating hard instances of lattice problems," STOC, 99-108 (1996)
Next Topics
This is a frontier survey topic. Explore individual directions as they develop in the research literature.
Last reviewed: April 25, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
4- Common Probability Distributionslayer 0A · tier 1
- Law of Large Numberslayer 0B · tier 1
- Peano Axiomslayer 0A · tier 2
- Differential Privacylayer 3 · tier 2
Derived topics
1- Importance Samplinglayer 2 · tier 1
Graph-backed continuations