LLM Construction
Fused Kernels
Combine multiple GPU operations into a single kernel launch to eliminate intermediate HBM reads and writes. Why kernel fusion is the primary optimization technique for memory-bound ML operations.
Why This Matters
Consider a sequence of three element-wise operations: residual addition, layer normalization, and dropout. Without fusion, each operation is a separate GPU kernel. Each kernel reads its input from HBM, computes, and writes its output back to HBM. The next kernel reads that output from HBM to start its work. Three kernels produce three round-trips to HBM.
Hide overviewShow overview
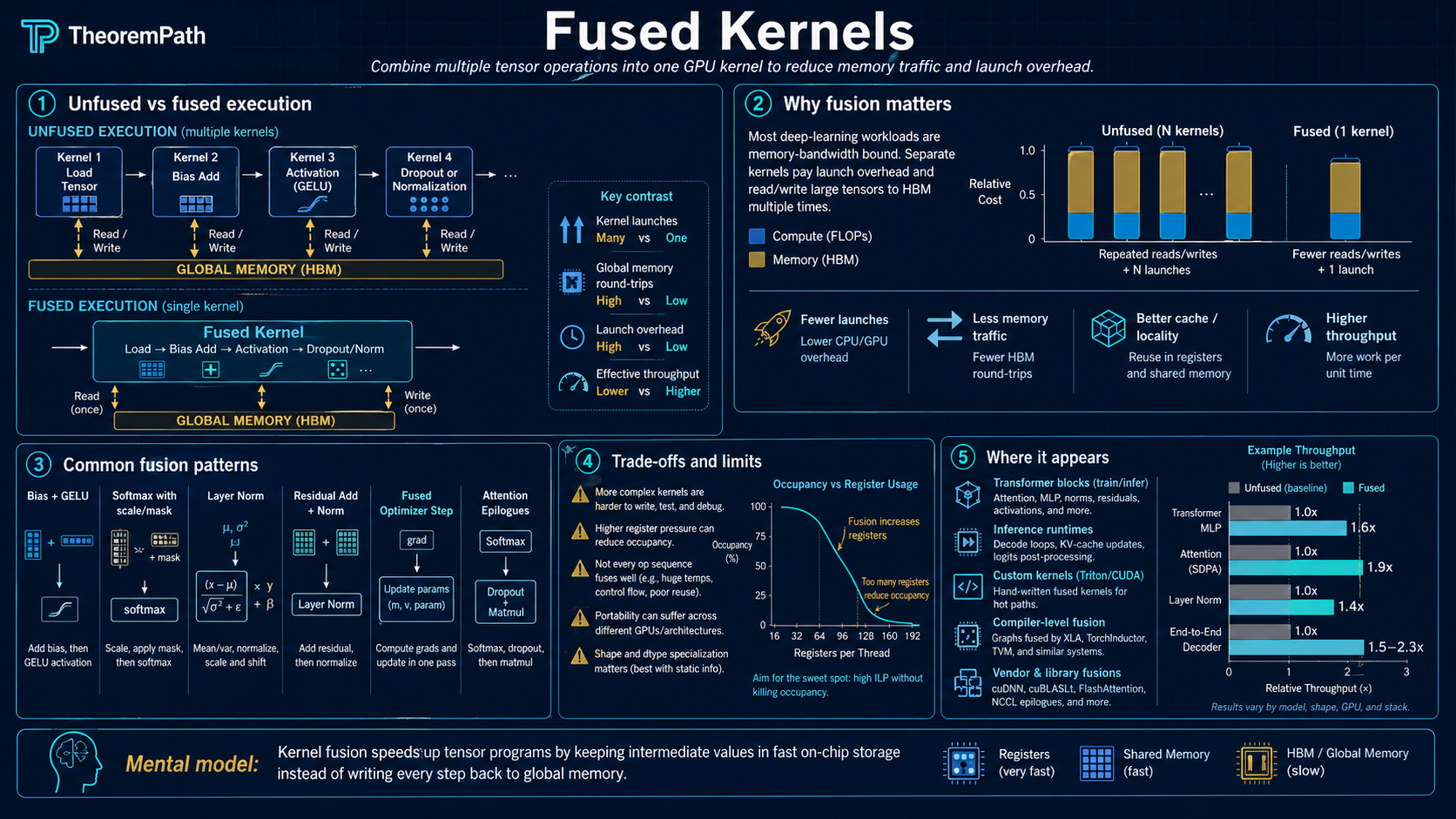
With fusion, all three operations are combined into a single kernel. The input is loaded from HBM once, all three operations are applied in registers or SRAM, and only the final result is written back. Two intermediate HBM round-trips are eliminated entirely.
Since these operations are memory-bound (arithmetic intensity near 1), eliminating HBM traffic translates directly into wall-clock speedup. Kernel fusion is how Flash Attention, xFormers, and most production ML inference engines achieve their performance.
Mental Model
Think of each GPU kernel as a factory worker who can only communicate by placing items on a shared conveyor belt (HBM). Without fusion, worker A puts intermediate results on the belt, worker B picks them up, processes them, and puts new results on the belt, worker C picks those up. Most time is spent loading and unloading the belt.
With fusion, a single worker does all three jobs internally, touching the belt only for the original input and final output.
The Problem: Unfused Operations
GPU Kernel
A function compiled for and launched on the GPU. Each kernel has a launch overhead (CPU dispatch, scheduling) and performs its own HBM reads and writes. The GPU kernel is the unit of work in CUDA and similar frameworks.
A typical transformer forward pass without fusion:
- QKV projection: read input from HBM, matmul, write QKV to HBM
- Attention scores: read Q, K from HBM, matmul, write scores to HBM
- Softmax: read scores from HBM, compute softmax, write to HBM
- Attention output: read softmax output and V from HBM, matmul, write to HBM
- Residual add: read attention output and residual from HBM, add, write to HBM
- Layer norm: read from HBM, normalize, write to HBM
- FFN: read from HBM, two matmuls with activation, write to HBM
Steps 2-4 involve three separate HBM round-trips for attention alone. Steps 5-6 involve two more. Each round-trip is wasted time because the intermediate values are consumed immediately and then discarded.
Main Theorems
IO Reduction from Kernel Fusion
Statement
Under the assumptions above, the unfused chain performs element HBM accesses (each of operations reads and writes ). With full fusion into a single kernel, the total HBM traffic is elements (one read of the original input, one write of the final output). The IO reduction factor for this specific case is .
Intuition
Fusion eliminates intermediate writes and intermediate reads. The only HBM access that remains is loading the initial input and storing the final output. Everything in between stays in registers or SRAM.
Proof Sketch
Each unfused kernel performs one read and one write of elements: total . The fused kernel loads elements, applies all operations in fast memory, and writes elements: total . Ratio: .
Why It Matters
For a chain of 5 same-shape element-wise operations (common in transformer blocks: residual add, dropout, scale, shift, activation), fusion reduces HBM traffic by . Since these operations are memory-bound, this translates to roughly wall-clock speedup for this portion of the computation.
Failure Mode
The clean factor is specific to chains of same-shape element-wise ops. Operations whose inputs and outputs have different shapes (matmuls, reductions, layer norm with its -elements input and -elements statistics, attention with its intermediate) require a different IO accounting. Fusion still helps in those cases, but the savings are not a simple factor of . Fusion also fails to help when: (1) intermediates are reused by other downstream kernels, (2) the fused kernel exceeds register/SRAM budgets and reduces occupancy, or (3) the chain is compute-bound rather than memory-bound.
Examples of Fused Kernels in Practice
Fused attention (Flash Attention): the softmax, scaling, and matmul with V are fused into a single tiled kernel. This is the biggest single fusion in modern transformers. FLOPs remain (the algorithm is not asymptotically cheaper). HBM read/write traffic drops from to where is on-chip SRAM size: a large constant-factor reduction, not a move to linear-in- HBM. The one genuine asymptotic win is peak activation memory, which drops from (the materialized attention matrix) to because the scores are never stored. See the FlashAttention page for the full IO analysis.
Fused layer norm + residual add: instead of writing the residual sum to HBM and reading it back for layer norm, combine both into one kernel. This eliminates one full tensor read-write cycle.
Fused activation + multiply (SwiGLU): following Shazeer 2020 (arXiv:2002.05202), the SwiGLU feed-forward block is with and . The inner is element-wise after the two projections: fusing the Swish activation with the element-wise multiply avoids writing the intermediate gate tensor to HBM.
Fused softmax + cross-entropy loss: instead of computing softmax, writing probabilities to HBM, then reading them back to compute the loss, do both in one kernel. This also avoids materializing the full probability vector, which saves memory for large vocabularies.
Writing Fused Kernels with Triton
CUDA requires writing kernels in C/C++ with explicit thread and memory management. Triton (OpenAI) provides a Python-based DSL for writing GPU kernels that compile to efficient GPU code. Key features:
- Automatic memory coalescing and shared memory management
- Block-level programming model (operate on tiles, not individual threads)
- Just-in-time compilation to PTX/SASS
- Dramatically lower development effort than raw CUDA
A fused layer norm kernel in Triton is roughly 40 lines of Python. The equivalent CUDA kernel is 200+ lines of C++. Performance is comparable because Triton's compiler handles the low-level optimizations.
When Fusion Helps and When It Does Not
Fusion helps when:
- Operations are memory-bound (low arithmetic intensity)
- Intermediate results are used once and then discarded
- The chain of operations fits in the register/SRAM budget per thread block
Fusion does not help when:
- The bottleneck is compute, not memory (large matmuls already achieve high utilization)
- Intermediate results must be reused by multiple downstream operations
- The fused kernel becomes so large that register pressure reduces occupancy below the level where the GPU can hide memory latency
Common Confusions
Kernel fusion does not reduce FLOPs
Fusion performs the exact same floating-point operations as the unfused version. The speedup comes entirely from eliminating redundant HBM traffic. If anything, fusion may add a small overhead from more complex control flow within the single kernel.
Not all operations should be fused
Fusing a large matmul with a small element-wise operation may not help if the matmul already achieves high compute utilization. The element-wise operation's memory traffic is negligible compared to the matmul's compute time. Fusion adds implementation complexity without meaningful speedup.
Triton is not a replacement for all CUDA
Triton excels at element-wise, reduction, and attention-like kernels. For operations requiring warp-level primitives, shared memory bank conflict management, or tensor core scheduling, hand-written CUDA may still be necessary. Triton's abstraction level prevents some low-level optimizations.
Common fake understanding: fusion vs algorithmic FLOP savings
Three distinct claims get conflated. (a) Kernel fusion reduces memory traffic by keeping intermediates in registers or SRAM; it does not change the FLOP count. (b) Kernel fusion does not reduce FLOPs, full stop: the same arithmetic runs, just with fewer HBM round-trips. (c) Some algorithms (for example a hypothetical subquadratic attention) reduce asymptotic FLOPs by changing the computation itself; FlashAttention is not one of them. FlashAttention is a tiled fused kernel whose win is in the memory hierarchy, not in FLOP count. Saying "FlashAttention is faster because it does less work" is the fake understanding; the correct statement is "FlashAttention is faster because it moves far less data to and from HBM for the same work."
Summary
- Kernel fusion eliminates intermediate HBM reads and writes between consecutive operations
- For a chain of memory-bound operations, fusion reduces IO by a factor of
- Flash Attention is a fused tiled kernel: softmax, scaling, and matmul with V in one pass. FLOPs stay ; HBM traffic drops to ; peak activation memory drops from to . See FlashAttention.
- Triton makes writing fused kernels accessible from Python
- Fusion helps memory-bound operations; it does not help compute-bound operations
Exercises
Problem
A transformer layer applies (in sequence): residual addition ( elements read and written), layer norm ( elements read and written), and dropout ( elements read and written). Each operation is a separate kernel. How many total HBM reads and writes occur? How many with full fusion?
Problem
Flash Attention fuses the computation into a single tiled kernel. Explain why this fusion is more complex than fusing element-wise operations. What specific challenge does the softmax normalization introduce, and how is it resolved?
References
Canonical:
- NVIDIA, CUDA Programming Guide, chapter on kernel optimization and the CUDA Graphs section (kernel launch capture and replay to amortize launch overhead across fused graph regions).
- NVIDIA, CUTLASS (CUDA Templates for Linear Algebra Subroutines), template library for fused GEMM, GEMM + epilogue, and tensor-core kernels.
- Dao, Fu, Ermon, Rudra, Ré, FlashAttention (2022), Sections 3-4.
- Shazeer, GLU Variants Improve Transformer (2020), arXiv:2002.05202 (SwiGLU convention used above).
Current:
- Tillet, Kung, Cox, Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations (MAPL 2019).
- Ansel et al., PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation (ASPLOS 2024), the torch.compile / TorchInductor paper. TorchInductor emits fused Triton kernels for pointwise and reduction regions.
- PyTorch team, FlexAttention (2024), a Triton-backed attention DSL that fuses arbitrary score modifications with the tiled attention kernel without writing the score matrix.
- Spector, Thakkar, Arora, Dao, Ré, ThunderKittens (Stanford, 2024): a tile-centric CUDA framework for writing fused kernels at tensor-core throughput.
- NVIDIA Apex, FusedAdam and related fused optimizers (
apex.optimizers.FusedAdam): the per-parameter Adam update is fused into a single kernel over all parameter tensors, eliminating per-tensor launch overhead and intermediate HBM traffic. - NVIDIA, Transformer Engine documentation (fused kernels for FP8 transformer training).
Last reviewed: April 26, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
5- WebGPU for Machine Learninglayer 0B · tier 2
- Flash Attentionlayer 5 · tier 2
- GPU Compute Modellayer 5 · tier 2
- CUDA Programming Fundamentalslayer 4 · tier 3
- NVIDIA GPU Architectureslayer 5 · tier 3
Derived topics
1- Megakernelslayer 5 · tier 3
Graph-backed continuations